#biologically_inspired
Fast Weights
src:
Ordinary RNN/LSTM neural networks have two kinds of memory. The weights of the ordinary neural network can be thought of as the long-term memory,1 For some reason, I never thought of the weights as that. Actually, upon further inspection, it seems weird to me that we do this. When I think of a neural network and its weights, I’m thinking usually about it as a compute engine, and these are just the current configuration that enables it to do things. Things are again getting a little philosophical/neuroscience, in that what exactly is being stored in our brains? Do we know how memory is stored? while the memory hidden vector can be thought of as the short-term memory.
RNNs have a hidden vector2 which in class I relate to HMMs, basically as latent variables that can also be thought of as some form of short-term memory. which gets updated at each recurrent step, so it’s pretty flaky. LSTMs on the other hand try to make this memory more sticky by computing increments to the hidden vector, thereby allowing memory to persist for longer.
One would expect that something in between these two kinds of memory might be useful (more storage capacity than short-term, but also faster than long-term).
The argument is made based on a temporal-scaling issues: working memory/attention operate on the timescale of 100ms to minutes. The brain, meanwhile, implements these intermediate short-term plasticity mechanisms via some weird biology
Calculus for Brain Computation
Figure 1: How fruit flies remember smells
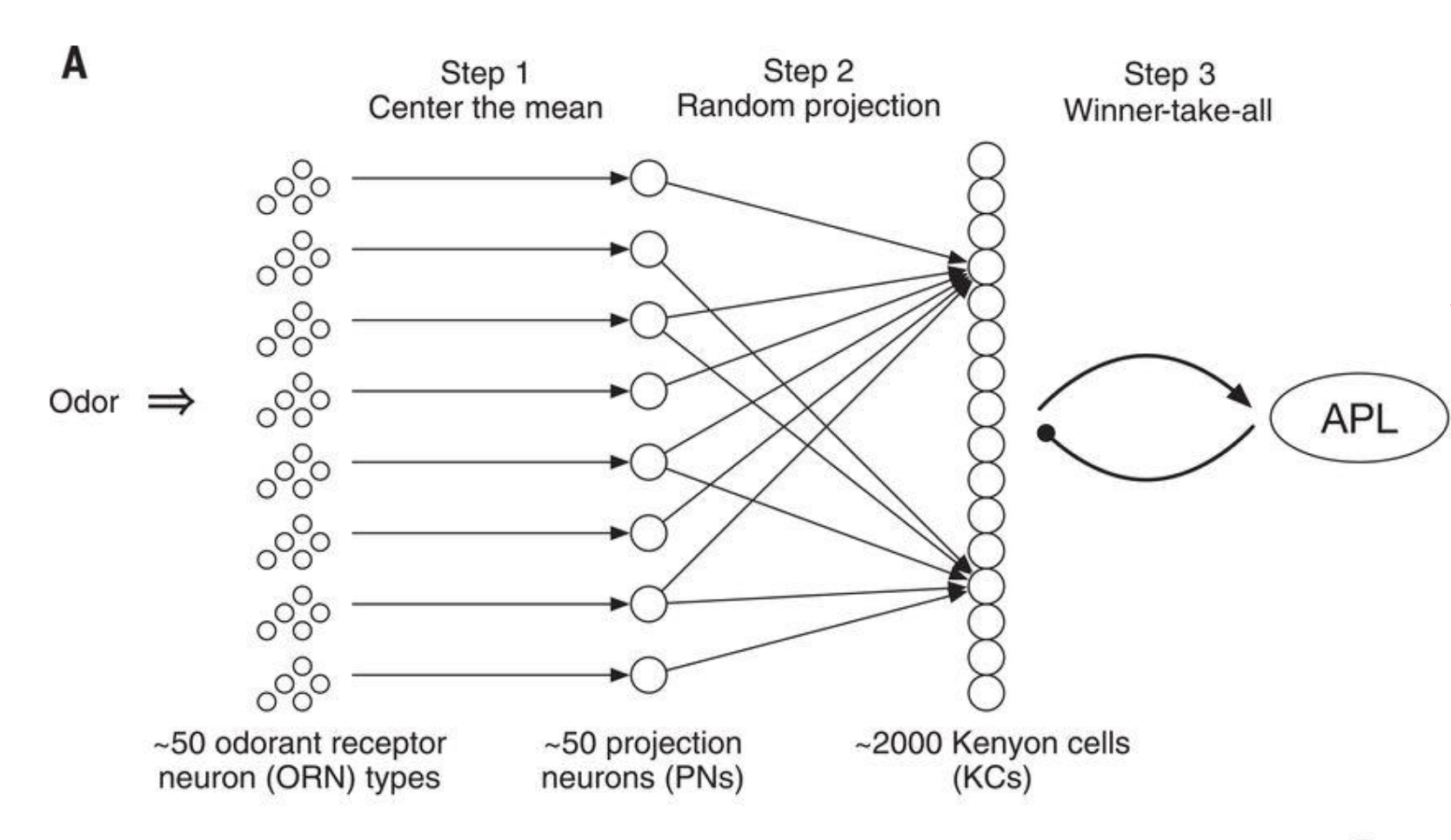
- olfactory intelligence: centering -> random projection (50 to 2000) -> sparsification
- \(\mathbb{R}^{50} \to \mathbb{R}^{2000} \to \{0,1\}^{2000}\) (sparsity at the 10% level, thresholding the top).
Figure 2: Random projection preserves similarity.
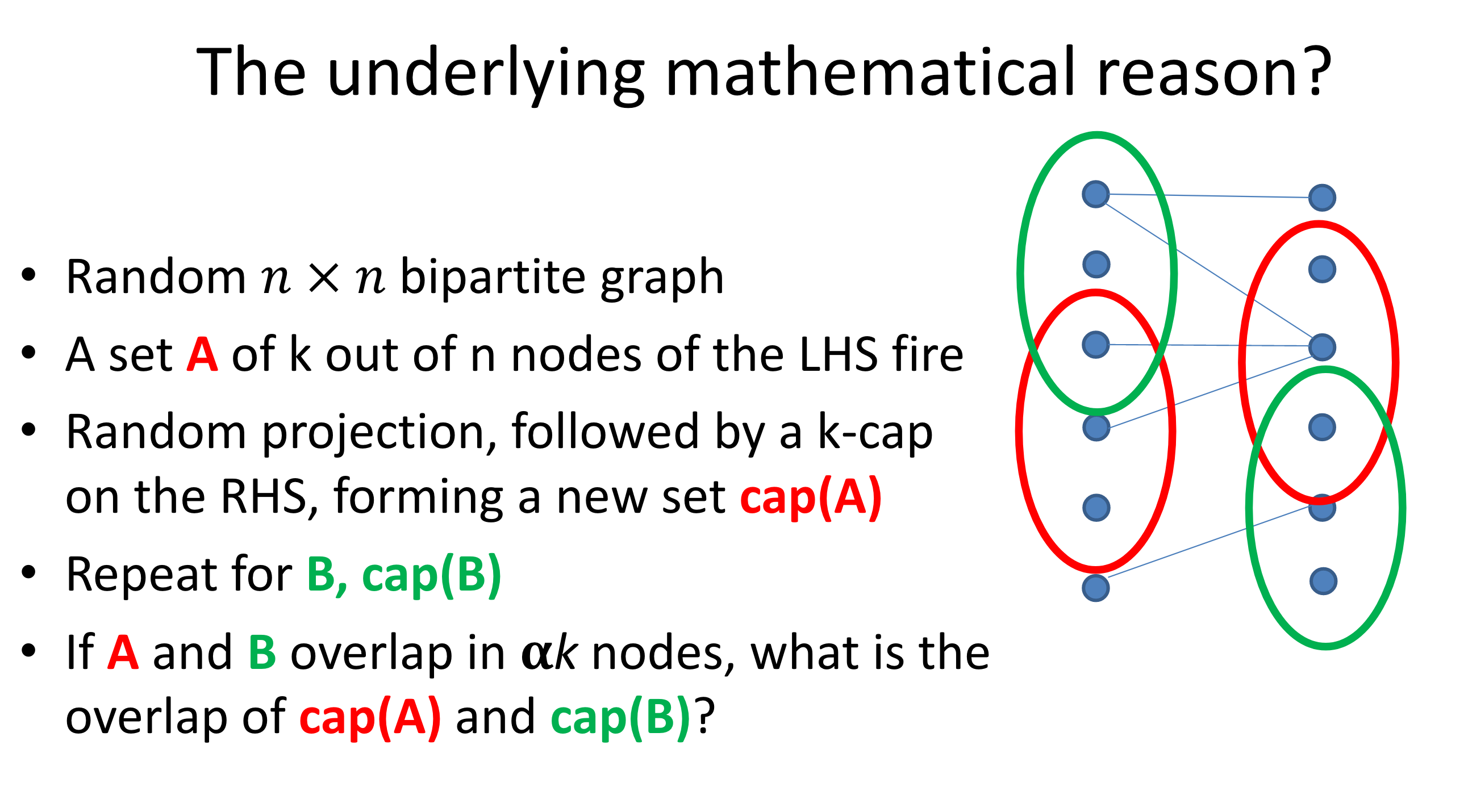
- similarity is preserved by this (random-projection+threshold) procedure; similarity here defined by overlap
- not really sure what you’re gaining though?1 I guess, the idea is that you have a sparse representation (binary vector that can be captured by binary-firing neurons). perhaps storage, like with computers, just has to be in binary, so there’s nothing particularly profound here.
- Calculus of the Brain
- interesting experiment: have a neuron only fire when you see eiffel tower (vs house or obama)
- then super-impose obama onto eiffel tower, Fig. 3
- now show Obama, and the neuron will fire (most of the time)
- what’s going on?
- one way you can think of this is that there’s the set of neurons that fire for eiffel (memory of eiffel), and similarly for other objects
- when you see two things together (learning relationships, causality, hierarchy), then what happens is that these two sets of neurons are now connected/merged
- but in order for this to make sense, the merge operation needs to be a little bit elaborate. basically you have to create the merged version (so like eiffel+obama), and perhaps that becomes the channel that connects the two things?
- this basically gives you something like a calculus on the brain, basically involving set operations on neurons
- interesting experiment: have a neuron only fire when you see eiffel tower (vs house or obama)
 Figure 3: Ison et al. 2016 Experiment
Figure 3: Ison et al. 2016 Experiment