#education
Power Tower
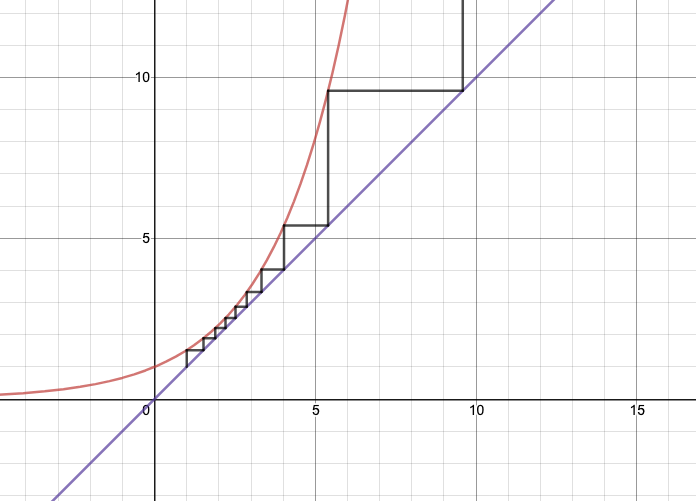 Figure 1: Power Tower for \(b = 1.52\)
Figure 1: Power Tower for \(b = 1.52\)
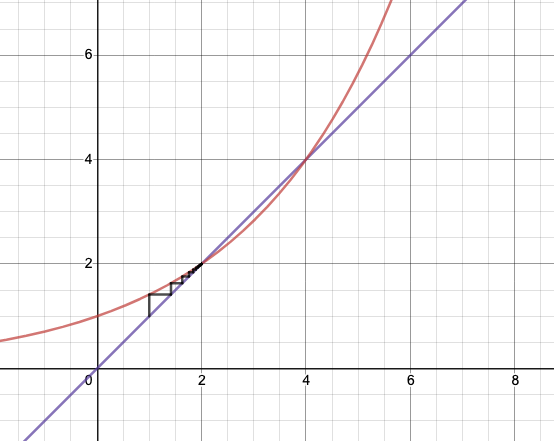 Figure 2: Power Tower for \(b = 2^{1/2}\)
Figure 2: Power Tower for \(b = 2^{1/2}\)
- very simple but cool mathematics: consider the power tower \(x^{x^{x^x}}\)
- for \(x=2\), this blows up at the 6th iteration
- what about for \(x=1.1\)?
- my intuition was that this would also blow up pretty quickly, but nope.
- it basically stabilizes:
- solve \(x^{x^{\cdot^{\cdot^{\cdot}}}} = y\) for some constant \(y\), where \(x = 1.1\)
- note that by the property of \(\infty\), we have \(1.1^y = y\)
- so the limiting factor is the solution to that equation.
- if \(y=4\), what value of \(x\) converges to that?
- \(x^4 = 4 \implies x = \sqrt{2}\).
- but what about \(y=2\)?
- \(x^2 = 2 \implies x = \sqrt{2}\)…as well. oops.
- solve \(x^{x^{\cdot^{\cdot^{\cdot}}}} = y\) for some constant \(y\), where \(x = 1.1\)
- to see what’s going on, just look at Figure 1
- using the cobweb, which is a way to get a progression:
- \(a_0 = 1, a_i = b^{a_{i-1}}\)
- depending on the value of \(b\) (which defines the \(y=b^x\) graph), you’re going to get different behaviour
- the fun thing is that you can’t really tell this unless you draw the graph
- using the cobweb, which is a way to get a progression:
- in particular this (Figure 2) explains the weird thing that happens at \(\sqrt{2}\)
- the reason it doesn’t work is that when you set \(y=4\), and do the substitution of the power-tower on itself, that operation only works if it exists, but it doesn’t, so it’s illegal.
- if you could somehow do it in reverse, then you’d get the \(y=4\), maybe.
New Linear Algebra
New way to teach linear algebra.
\[ \begin{align*} Ax = \begin{bmatrix} 1 & 4 & 5 \\ 3 & 2 & 5 \\ 2 & 1 & 3 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix} = \begin{bmatrix} 1 \\ 3 \\ 2 \end{bmatrix} x_1 + \begin{bmatrix} 4 \\ 2 \\ 1 \end{bmatrix} x_2 + \begin{bmatrix} 5 \\ 5 \\ 3 \end{bmatrix} x_3 \end{align*} \]
- \(Ax\) is basically a linear combination of the columns
- column space \(C(A)\) is the space spanned by the (3) columns, though since the first two columns add up to the second, it’s just two vectors (rank 2).
\(A = CR\)
\[ \begin{align*} A = CR = \begin{bmatrix} 1 & 4 \\ 3 & 2 \\ 2 & 1 \end{bmatrix} \begin{bmatrix} 1 & 0 & 1 \\ 0 & 1 & 1 \end{bmatrix} \end{align*} \]
- getting independent columns, which is the basis for the column space.
- clearly, you can always do this
- it’s just that sometimes it’s not interesting (i.e. if it’s already a basis)
- \(R\) is the basis for the row space, also rank 2
- number of independent columns = \(r\) = number of independent rows
- \(\operatorname{rank}(C(A)) = \operatorname{rank}(R(A))\)
- \(Ax = 0\) has one solution, and there are \(n-r\) independent solutions to \(Ax = 0\)
- \(R\) turns out to be the row reduced echolon form of \(A\)
\(Ax = 0\)
\[ \begin{align*} \begin{bmatrix} \text{row } 1 \\ \vdots \\ \text{row } m \end{bmatrix} \begin{bmatrix} \\ x \\ \, \end{bmatrix} = \begin{bmatrix} 0 \\ \vdots \\ 0 \end{bmatrix} \end{align*} \]
- 0 on the right means that the rows must all be orthogonal to \(x\)
- i.e. every \(x\) in the nullspace \(N(A)\) must be orthogonal to the row space.
- if you take transposes you get the equivalent statement for column space
Figure 1: Big Picture Linear Algebra

\(A = BC\)
\[ \begin{align*} A = BC = b_1 c_1^* + b_2 c_2^* + \ldots \end{align*} \]
- here, \(b_i\) are the column vectors of \(B\), while \(c_i^*\) are the row vectors of \(C\).
- you can think of matrix also as column by row multiplication
- it’s more like building blocks there, adding up rank 1 matrices
\(A = LU\)
- you can rewrite \(A\) as a product of lower-triangular and upper-triangular matrices.
- that’s what you’re doing when you’re solving simultaneous equations by elimination
\(Q^\top Q\)
- \(Q\) with orthogonal(normal) column vectors, such that \(Q^\top Q = I\)
- not necessarily true that \(QQ^\top = I\), if not square
- \(QQ^\top\) is like projection:
- \(QQ^\top QQ^\top = QQ^\top\)
- if square, then \(QQ^\top = I\) and \(Q^\top = Q^{-1}\)
- length is preserved by \(Q\)
\(A=QR\)
- Gram-Schmidt: orthogonalize the columns of \(A\).
- assuming full rank of \(C(A)\)
- \(Q^\top A = Q^\top Q R = R\)
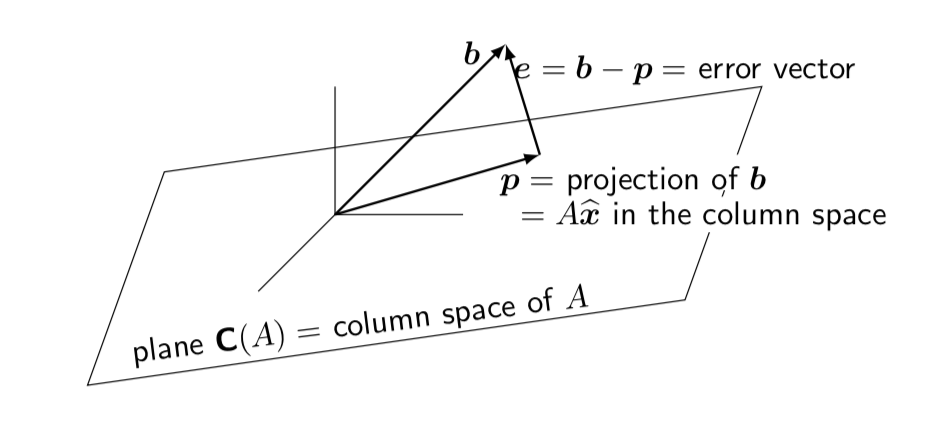
- Major application: Least Squares
- want to minimize \(\norm{b - Ax}^2 = \norm{e}^2\)
- normal equation for minimizing solution (best \(\hat{x}\)): \(A^\top e = 0\)
- if \(A = QR\), then you get \(R \hat{x} = Q^\top b\)
Figure 2: Least Square
\(S = Q \Lambda Q^\top\)
- symmetric matrix \(S=S^\top\) have orthogonal eigenvectors
- how to show \(x^\top y = 0\)
- \(Sx=\lambda x \implies x^\top S^\top = \lambda x^\top \implies x^\top S y = \lambda x^\top y\)
- \(Sy=\alpha y \implies x^\top S y = \alpha x^\top y\)
- hence, \(\lambda x^\top y = \alpha x^\top y\). but \(\lambda \neq \alpha\), since eigenvalues are distinct
- hence, \(x^\top y = 0\)
- things are not nice when things aren’t square
- but \(A^\top A\) is always square, symmetric, PSD
- same holds for \(AA^\top\)
- same eigenvalues
- \(x \to Ax\) to convert eigenvectors
- from definition of eigenvalues: \(AX = X \Lambda\)
- if you don’t have symmetry, then you can’t just hit it with \(X^\top\) and get things to cancel
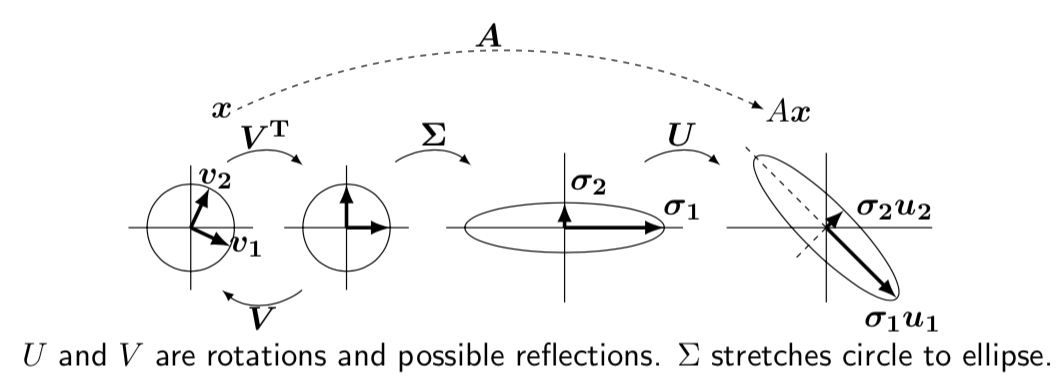
\(A = U \Sigma V^\top\)
- \(U^\top U = I, V^\top V = I\)
- \(AV = U \Sigma\) (like the eigen-decomposition, but not quite)
- \(Av_i = \sigma_i u_i\)
- \(U, V\) are rotations, \(\Sigma\) stretch.
- how to choose orthonormal \(v_i\) in the row space of \(A\)
- \(v_i\) are eigenvectors of \(A^\top A\) (which are orthonormal, from above)
- \(A^\top A v_i = \lambda_i v_i = \sigma_i^2 v_i\)
- so then \(A^\top A V = \Sigma^2 V\)
- how to choose \(u_i\)
- \(u_i = \frac{1}{\sigma_i} A v_i\)
- check orthonormal: \(u_i^\top u_j\)
- combining, \(A^\top A v_i = \sigma_i^2 v_i \implies A^\top u_i = \sigma_i v_i\)
Figure 3: Singular Value Decomposition