#neuroscience
Learning as the Unsupervised Alignment of Conceptual Systems
src: (Roads and Love 2020Roads, Brett D, and Bradley C Love. 2020. “Learning as the unsupervised alignment of conceptual systems.” Nature Machine Intelligence 2 (1): 76–82.)
The surprising thing about * embeddings is that it relies solely on co-occurrence, which you can define however you want. This makes it a powerful generalized tool.1 And more generally, a key insight in statistical NLP is to not worry (too much) about the words themselves (except maybe during the preprocessing step, with things like stemming), but simply treat them as arbitrary tokens. For example, as in this paper, we can consider objects (or captions) of an image, and co-occurrence for objects that appear together in an image. From this dataset (Open Images V4: github), we can construct a set of embedding vectors (using GloVe) for the objects/captions (call this GloVe-img).
What is this set of embeddings? You can think of this as a crude learning mechanism of the world, using just visual data.2 Potential caveat (?): part of the data reflects what people want to take photos of, and be situated together. Though for the most part the objects in the images aren’t being orchestrated, it’s more just what you find naturally together. In other words, if a child were to learn through proximity-based associations alone, then perhaps this would be the extent of their understanding of the world.
A natural followup is, then, how does this embedding compare to the standard GloVe learned from a large text corpus?
At this point, I need to digress and talk about what this paper does:
- take the similarity matrix of the original GloVe vectors and the GloVe-img vectors. calculate the correlation of the matched entries. turns out that correlation can get as high as 0.3. perhaps that’s surprising?
- seems like a waste to project things down to a similarity matrix. on the other hand, the arbitrariness of embeddings might make it difficult to compare embeddings directly.
Rotation Dynamics in Neurons
src: (Libby and Buschman 2021Libby, Alexandra, and Timothy J Buschman. 2021. “Rotational dynamics reduce interference between sensory and memory representations.” Nature Neuroscience.)
Cognition, our intelligence, lies, in part, in our ability to synthesize what we see before us (our sensory input) with our store of data (memory, maybe working, maybe long-term). In other words, intelligence is the cumulation of a time-cascade of information. Now, supposedly, due to the “distributed nature of neural coding,” this can lead to interference between the various time-levels.
This part is a little confusing to me, so let’s work through this slowly. Suppose we take a computer as an artificial example: you essentially have different stores of data with different read speeds (which loosely proxy sensory (registers), short-term (RAM) and long-term (disk)).1 In computers, the changing variable is read-speed/distance. Perhaps in the brain, the changing variable is the dimension of the data? Clearly, if you had enough “space,” there wouldn’t be an issue of interference. But of course our brains aren’t constructed to have simple, isolated stores,2 Well, we have neurons, and groups of neurons feel a little like discrete stores. This is where the limits of my knowledge are a crux; I feel like there are things like memory neurons, different templates of (perhaps groups of) neurons. On the other hand, the heavily architected memory components of the latest #deep_learning models cannot possibly be how the brain functions. We’re still missing the #biologically_inspired bit here. so perhaps it’s not even about the space constraint, but just the nature of the form of the “data.”
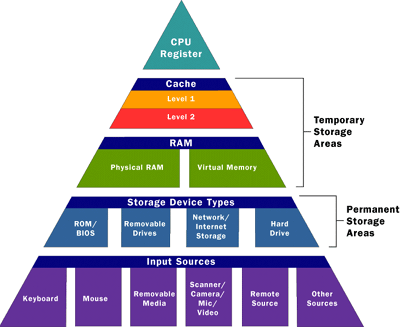 Figure 1: Computer Memory Pyramid
Figure 1: Computer Memory Pyramid
Let’s try and work backwards a little: why would our brains want to orthogonalize things? I think one of the key assumptions is that, for various reasons probably related to the protections afforded by redundancy and distributed representation (or even the noisy, arbitrary nature of life’s input), we represent information as high-dimensional vectors. Under this regime, then it really pays to utilize the whole space. How to do so? The most crude way would be to simply orthogonalize. But, actually, the fact that these vectors become orthogonal might just be a byproduct of some more complex process.
Backlinks
- [[loftus-and-memory]]
- Reading about the malleability of memory, and relating this to the recent ideas from #neuroscience on how our cells work through linear algebra (see [[rotation-dynamics-in-neurons]] and [[neural-code-for-faces]]), I wonder if there’s a similar way of coding the curious properties of memory as artefacts of linear algebra.
Calculus for Brain Computation
Figure 1: How fruit flies remember smells
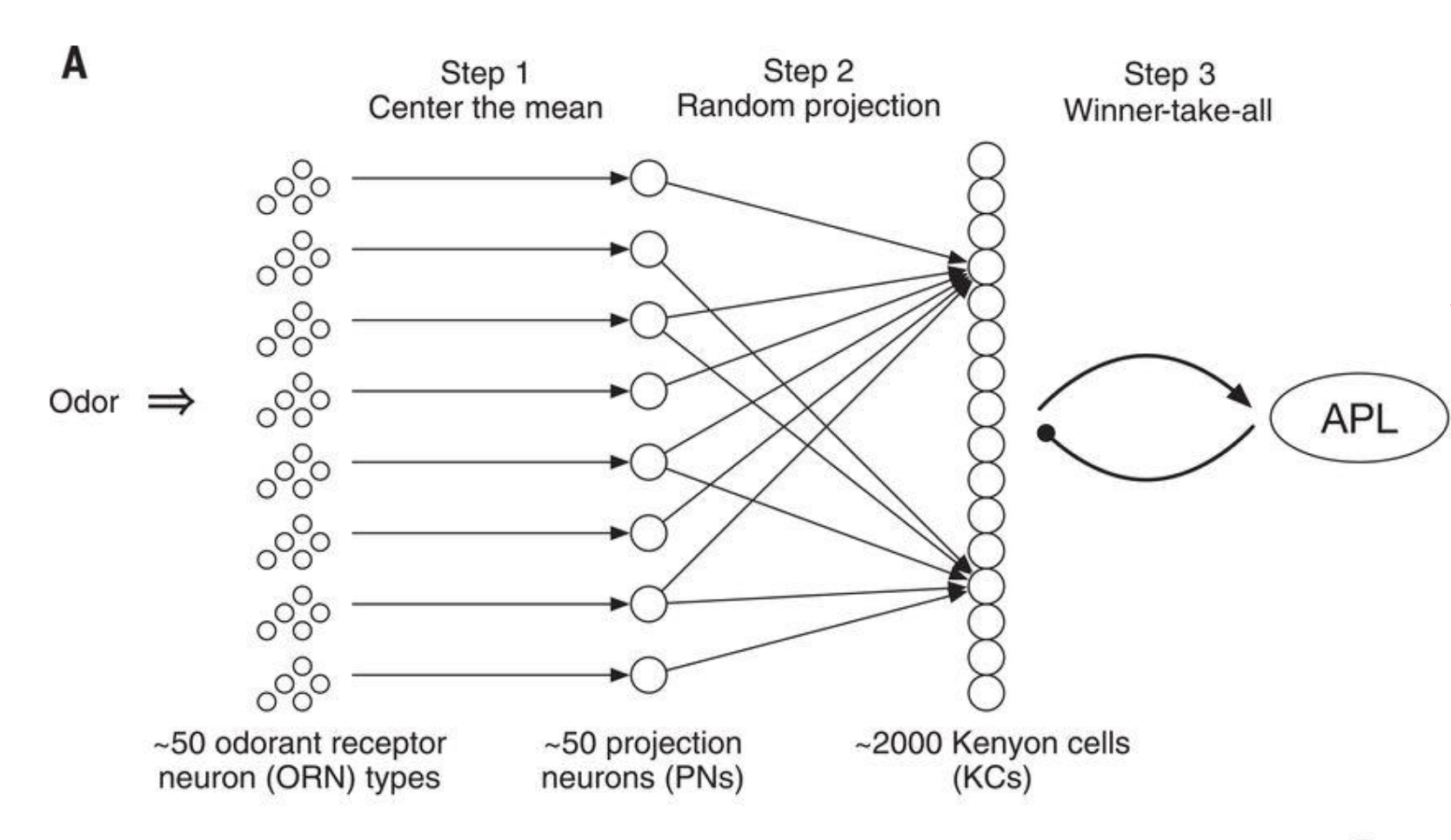
- olfactory intelligence: centering -> random projection (50 to 2000) -> sparsification
- \(\mathbb{R}^{50} \to \mathbb{R}^{2000} \to \{0,1\}^{2000}\) (sparsity at the 10% level, thresholding the top).
Figure 2: Random projection preserves similarity.
- similarity is preserved by this (random-projection+threshold) procedure; similarity here defined by overlap
- not really sure what you’re gaining though?1 I guess, the idea is that you have a sparse representation (binary vector that can be captured by binary-firing neurons). perhaps storage, like with computers, just has to be in binary, so there’s nothing particularly profound here.
- Calculus of the Brain
- interesting experiment: have a neuron only fire when you see eiffel tower (vs house or obama)
- then super-impose obama onto eiffel tower, Fig. 3
- now show Obama, and the neuron will fire (most of the time)
- what’s going on?
- one way you can think of this is that there’s the set of neurons that fire for eiffel (memory of eiffel), and similarly for other objects
- when you see two things together (learning relationships, causality, hierarchy), then what happens is that these two sets of neurons are now connected/merged
- but in order for this to make sense, the merge operation needs to be a little bit elaborate. basically you have to create the merged version (so like eiffel+obama), and perhaps that becomes the channel that connects the two things?
- this basically gives you something like a calculus on the brain, basically involving set operations on neurons
- interesting experiment: have a neuron only fire when you see eiffel tower (vs house or obama)
 Figure 3: Ison et al. 2016 Experiment
Figure 3: Ison et al. 2016 Experiment