#proj:penalty
Experimental Logs for MovieLens
Summary: many of the interesting patterns/phenomena that we see in the noiseless MC case (synthetic data) do not translate when we move to real-life data.1 What’s interesting is that part of me wants to argue like a theoretician, and say that it doesn’t really matter that it doesn’t work on real-life problems. It is slightly different to the way theoretical statistics works, because there the statistical models are usually motivated by solving some real-world problem (though again the same could be said for collaborative filtering). But somehow this feels a little different, as the low-rank matrix problem is a much more general problem than the optimal estimation rates of a particular statistical model. And plus we don’t actually make any claims about the noisy model. The simple answer is that the noisy problem is equalizing, and makes the problem almost trivial (?); that or the fact that the problem isn’t actually that low-rank, so it’s moot to run true low-rank algorithms.
Data
The data here is the MovieLens 100K. The matrix is roughly \(1000 \times 1000\), and so in fact we are only given around 10% of the data. Thus, the 80% split is actually a low-data regime, since we’re talking about seeing only around 8% of the total matrix (even though we never see the other 90%).
The question becomes: what is the most appropriate model for real-life data?
The most natural model would simply be low rank matrix + noise.2 A recent paper “Why Are Big Data Matrices Approximately Low Rank?” argues that many big data matrices that have some sort of latent representation are close to a low-rank representation (+ noise). Or, perhaps the noise is …
One might think of a more general model where there is some non-linear map (which I believe is what motivates the more Neural Collaborative Filtering). Though in this case, I wonder if the non-linear activation functions would be helpful.
Logs
Under the Full model: 80/20 train/test split that everyone uses.
- Obs: generally speaking, the rank in terms of performance is: \(2, 1, 3, 4, \ldots\)
- focusing on depth-1: this definitively refutes the conjecture that depth + GD is exactly equivalent to linear model + Adam + penalty.3 While I never believed it to be exactly equivalent, this result feels like actually there’s something crucial missing in the Adam version.
- what’s weird here is that basically depth 2 is the best, followed by 1. though I guess in the synthetic data, the only difference is that 2 and 1 are switched (the question is whether or not the same thing holds for GD).
- Obs: un-penalized vs penalized changes the effective rank, but doesn’t change the test error.
- this again is a weird one. firstly, it’s weird that it feels like the penalty basically has no effect, that it’s essentially the depth that is driving (and the optimization method) the generalization error.
- also, what we see is that effective rank has very little relation to generalization power.
- though, this is perhaps unsurprising in real-life data. that is why I like working in synthetic data, where there is a direct relation.
- that relation gets broken when you go overboard with the rank reduction at the expense of fitting the data.
Implicit Regularization
In the spirit of [[envisioning-the-future]], let’s think about the key questions in the area of implicit regularization.
The whole impetus for implicit regularization is an attempt to explain the phenomenon of how neural networks rarely (if ever) overfit, even without explicit penalties. Or at least that’s my interpretation of the goal. Having understood the exact mechanisms, one would hope that the insights should lead to more efficient algorithms.
In fact, that’s exactly the hope that [[project-penalty]] provides: in a very simple example, we see that we can replace implicit by explicit, to great effect.
In some sense, it’s all about trying to understand why deep learning is so effective, but there’s this implicit idea that somehow there are these biases, particularly in the choice of the gradient algorithm as well as the loss function itself, that are leading to choosing better generalizing minima. In other words, this is basically one approach to explaining the #generalization_conundrum.
Looking at the literature, people have been focused on trying to show that gradient descent is favoring solutions with smaller norms (and thankfully, solutions with smaller norms have better generalization performance).1 In fact, this was the impetus for looking at some other form of low-rank-ness, as I felt that it just so happens in many cases that good generalization equates to low norm/minimum rank, say.
One conclusion might be that the effects of implicit regularization are a black-box that cannot be replicated by explicit regularizers. But I think that would be a sad conclusion, as it would essentially say that there is basically no use to all this research.
I hold the more hopeful view that this analysis should lead to better training and understanding generalization, by replacing such black boxes with explicit renditions.
Another possibility is that a lot of the things that we’ve concluded about implicit regularization are only applicable in the narrow problem of matrix completion. Though I think you see similar things in linear regression right? So I guess that shouldn’t be true.
An important question is how things translate to more general settings, when you’re dealing with non-linear.
I really think that one of the lessons of deep learning is the [[the-unreasonable-effectiveness-of-adam]] (or normalization). That is, you should always pick normalized terms over convex terms, because convexity is overrated.
Story So Far
By focusing on linear neural networks, we can disentangle the over-parameterization effect from the expressivity of the model. Thus, what can we say about over-parameterization? It appears that, for any sort of problem where the weights form a full-product matrix (so matrix completion, matrix sensing), then running GD will favor low-rank matrices.
It is very tempting to say that there is some penalty being penalized. (Arora et al. 2019Arora, Sanjeev, Nadav Cohen, Wei Hu, and Yuping Luo. 2019. “Implicit Regularization in Deep Matrix Factorization.” arXiv.org, May. http://arxiv.org/abs/1905.13655v3.) show that the nuclear norm is not what’s going on, since they cleverly find a situation where the nuclear norm minimizer does not agree with the minimum rank minimizer. We show that actually the normalized nuclear norm does the trick.
The key thing here is that, we don’t believe that over-parameterization is equivalent to this explicit regularizer. In fact, there seems to be some accelerative effect going on, or some kind of smart normalizing thing, so clearly that too cannot be captured by a simple norm alone. What we want to show is that this is the most reasonable proxy (and it has nice gradient properties).
Recent paper (Razin and Cohen 2020Razin, Noam, and Nadav Cohen. 2020. “Implicit Regularization in Deep Learning May Not Be Explainable by Norms.” arXiv.org, May. http://arxiv.org/abs/2005.06398v1.) suggests that the implicit regularization is actually the rank itself. This doesn’t really make much sense: the rank is discrete, and as such is not particularly useful. If on the other hand you decide to look at its continuous version (like effective rank), then it’s just a question of which proxy do you pick, and at that point you might as well just pick ours, since you can actually take gradients.
Next Steps
The whole purpose of this, as we recall, is to say something about generalization for deep learning, which is complicated by various architectural features and non-linear components. In such cases, it is no longer possible (I don’t think?) to disentangle the over-parameterization from the expressivity. But my feeling is that this is just a technical nuisance. The spirit should still remain.
In our very special setting, we can show exactly what effect over-parameterization is doing, and that such a method perfectly solves the problem (so there’s basically no tuning/initialization worries). However, once you move into more complicated models, my feeling is that this surprise that deep learning does so well in terms of generalization is no longer such an exact/perfect situation. What I mean is that there’s a lot of tuning going on in the background to make these things generalize, but the surprise is still there: it’s still surprising that with just a little bit of tweaking, you’re able to find the solution that does generalize.
The point of this is that as you get into more complicated models, this generalization performance is more of an art, and, as such, we should expect that the resolution to the conundrum should also be more artful than the precise, simple, explicit way that was laid out in the cited papers.
What would be great would be some kind of information or sparsity measure that holds for general models, but when specialized down to linear neural networks, collapses to the singular values of the product matrix.
One of the worries that I have is that all of this just doesn’t really generalize past linear neural networks, for the simple reason that a lot of the success of deep learning comes from these carefully constructed architectures for a specific data type, which suggests that there is something inherent in the data itself (some inductive bias in the distribution of pixels, for instance), and which this kind of theory has no way of capturing.2 This was inspired by the last paragraph of this blog article: “I don’t see how to use the above ideas to demonstrate that the effective number of parameters in VGG19 is as low as 50k, as seems to be the case. I suspect doing so will force us to understand the structure of the data (in this case, real-life images) which the above analysis mostly ignores.”
Or, another way to put this is that, these previous results suggest that any old over-parameterized neural network should have all these nice sparsity-inducing, acceleration-type properties. Though, maybe the key ingredient is: some sort of alignment with the kinds of sparsity that the data possesses.3 This must somehow relate to the whole sparsity of image data in the Fourier domain. In other words, this notion of convolution (which I imagine was biologically inspired) might already have been optimized such that gradient methods4 hmmm, but biology doesn’t work via gradients, so not sure if this makes sense produce sparsity of the right kind.
Experimental Logs for Matrix Completion
Logs
Here we focus on the linear model (depth-1) version.
- Obs: if you look at the pattern of convergence, you find that generally speaking the first thing that happens is that the training error gets to zero (interpolation regime).
- this led us to try to initialize at the partially observed data, which works!
- Obs: Adam works very well, but GD works pretty well too. By work well, I am talking about getting decently close to the true singular vectors.1 This is achieved by tracking the inner product of the singular vectors of the estimated matrix and the true singular vectors.
- Obs: actually, even if you use the nuclear norm, you’re going to get “pretty good” results, in that the inner products are getting close to 1.
- my intuition was that the difficulty with this problem was getting anywhere close to the right directions for the singular vectors. In my mind, that seemed to be the difficult thing, so the fact that PGD was pushing it pretty uniformly towards the truth, I thought was a sign that something important was going on.2 This is not a reason, but also, many proofs (in the matrix factorization case) are of the form whereby you have to be clever with your initialization so that you can get into the basin, at which point the problem becomes strongly convex.
- But as it turns out, the difficulty at this level is at the last mile, so to speak. For instance, we already know that the nuclear norm minimizer is no longer the optimal solution. But it’s not like this solution is completely off.
- Obs: the nuclear norm minimum solution in the data-poor regime has decently high inner product with the ground truth singular vectors (\(\approx 0.9\)).
- thus, we have to focus on being able to essentially recover it exactly. Originally I thought some kind of SVD would do the trick, but I don’t think that’s the case.
- Obs: the ratio minimum should coincide with that of the rank. The nuclear norm minimum has higher ratio than the truth, and the sub-optimal solution that the PGD will converge to is also larger than the truth.
- Obs: if you compare the distribution of the singular values, we see that the top ones are smaller, while the bottom are larger (nuclear vs ratio, and ratio vs truth). Essentially, it’s able to find something that is able to match the observations but have smaller nuclear norm.
- this suggests that there are suboptimal optima (that somehow Adam is able to side-step). It feels that this ratio is better able to handle the data-sparse regime. Fig. 1 shows the trade-off that the nuclear norm creates, whereas the ratio penalty doesn’t make the same mistake.
- keep in mind though that the singular vectors are not exactly exactly the same either. so both are perturbed.
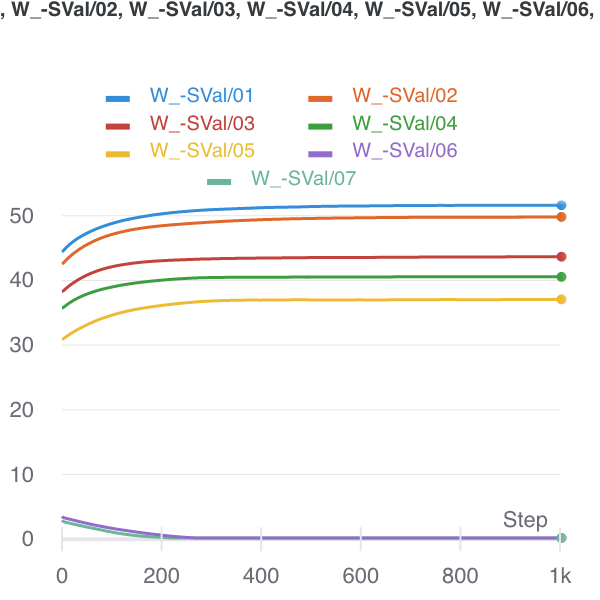 Figure 1: Nuclear Norm minimizer (initialized there) to Ratio Local minimizer.
Figure 1: Nuclear Norm minimizer (initialized there) to Ratio Local minimizer.
- Obs: even moving to rank-1, what we can see that the top singular value is dampened, and a collection of small singular vectors/values are able to recreate that loss in the magnitude.
- basically, the problem is, for a given set of entries (I think they can be arbitrary, even though they’re proportional to the true matrix), with a fixed cost for the total norm, but complete freedom with respect to everything else, can you recreate those entries?
- It would be interesting to investigate why our ratio fails: is it a similar kind of failure, where you’re moving some of the mass from the top to the bottom; or, as I expect, it’s going to be a more catastrophic failure, whereby all structure is destroyed, and so it’s basically hopeless to find the truth?
- From Fig. 2, it looks like what happens when the ratio fails, is that you basically start to separate out the singular values. The singular vectors are still roughly right. This suggests something even more elaborate that takes into account variability. Perhaps the spectral norm (max singular value) might do the trick (though this does not admit a computationally-efficient form/gradient).
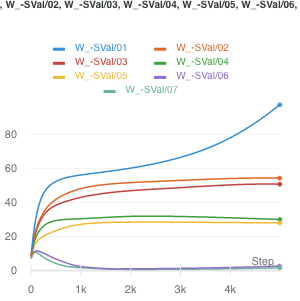 Figure 2: How the ratio penalty fails, with sample size of 1200.
Figure 2: How the ratio penalty fails, with sample size of 1200.
- Obs: trying the noisy version of PGD doesn’t actually do anything.
- feels like it’s not saddle points, so there are actually local minima in the landscape induced by this ratio penalty.
Conclusion
Define \(S^m = \left\{ M : P_{\Omega}(M - M^\star) = 0; \abs{\Omega} = m \right\}\). Then, as you decrease the sample size, \(\abs{\Omega}\), this set grows. For the most part, the nuclear norm min in \(S\) is the truth. But, at some point, this is no longer the case. Let’s actually define an increasing sequences of sets \(\Omega^m\). Then, \(S^m \supset S^{m+1}\). At that point, there is a matrix in \(S^m \setminus S^{m+1}\) with smaller nuclear norm.
From the experiments, it appears that at this boundary condition, this matrix with smaller nuclear norm is very similar to the true matrix. Qualitatively, it seems as if it’s been perturbed, and the singular values dampened, and then noisy singular vectors are introduced to reconstruct the observed entries. Unfortunately, I can’t really think of a principled manner in which to demonstrate this. Perhaps the most fruitful thing here would be to argue in terms of the two norms.
Suppose we’re at the truth (\(M^\star\)). Then perhaps one way to think about what happens is the following: we can always take a step in the direction of the gradient of the nuclear norm from the truth. It just so happens that once your \(S^m\) is sufficiently small, that projection step no longer counteracts the change in norm.
Backlinks
- [[matrix-factorization-to-linear-model]]
- Update: following on from [[experimental-logs-for-matrix-completion]], we have looked at how the nuclear norm fails in the depth-1 case, which is that you dampen the top singular values and reconstruct the residuals from small singular vectors (feels ever so slightly like [[benign-overfitting-in-linear-regression]]).
Matrix Completion Optimization
Let’s try to understand the landscape of optimization in matrix completion.
Matrix Factorization
A celebrated result in this area is (Ge, Lee, and Ma 2016Ge, Rong, Jason D Lee, and Tengyu Ma. 2016. “Matrix completion has no spurious local minimum.” In Advances in Neural Information Processing Systems, 2981–9. University of Southern California, Los Angeles, United States.). They consider the matrix factorization problem (with symmetric matrix, so that it can be written as \(XX^\top\)). Note that this problem is non-convex.1 The general version of this problem, with \(UV^\top\), interestingly, is at least alternatingly (marginally) convex (which is why people do alternating minimization). Under some typical incoherence conditions,2 To ensure that there is enough signal in the matrix, preventing cases where all the entries are zero, say. they are able to show that this optimization problem has no spurious local minima. In other words, for every optima to the function \[ \begin{align*} \widetilde{g}(x) = \norm{ P_\Omega (M - X X^\top) }_F^2, \end{align*} \] it is also a global minima (which means \(=0\)).3 They were inspired, in part, by the empirical observation that random initialization sufficed, even though all the theory required either conditions on the initialization, or some more elaborate procedure.
Proof technique: they compare this sample version \(\widetilde{g}(x)\) to the population version \(g(x) = \norm{ M - X X^\top }_F^2\), and use statistics and concentration equalities to get desired bounds.
Remark. The headline (no spurious minima) sounds amazing, but it’s not actually that non-convex. In any case, as it turns out, it’s basically non-convex (i.e. multiple optima) because you have identifiability issues with orthogonal rotations of the matrix (that cancel in the square). I wonder if the incoherence condition is important here. I don’t think so, as it’s a pretty broad set, so it really does seem like this problem is pretty well-behaved.
A nice thing about the factorization is that zero error basically means you’re done (given some conditions on sample size), since having something that factorizes and gets zero error must be the low-rank answer.To reiterate, they don’t use any explicit penalty (except something that’s helpful for the proof technique to ensure you are within the coherent regime). The matrix factorization form suffices.
Important: something I missed the first time round, but actually makes this somewhat less impressive: they basically assume the rank is given, and then force the matrix to have that dimension. This differs from (Arora et al. 2019Arora, Sanjeev, Nadav Cohen, Wei Hu, and Yuping Luo. 2019. “Implicit Regularization in Deep Matrix Factorization.” arXiv.org, May. http://arxiv.org/abs/1905.13655v3.)’s deep matrix factorization as there they aren’t forcing the dimensions. This doesn’t seem that impressive anymore.
Non-Convex Optimization
src: off-convex.
The general non-convex optimization is an NP-hard problem, to find the global optima. But even ignoring the problem of local vs global, it’s even difficult to differentiate between optima and saddle points.
Saddle points are those where the gradients in the direction of the axis happen to be zero (usually one is max, the other is a min). In the case of gradient descent, since we move in the direction of gradient for each coordinate separately, then we’re basically stuck.
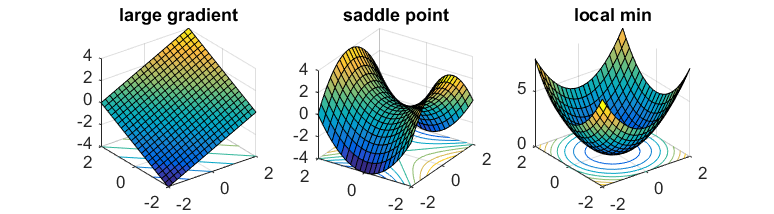
If one has access to second-order information (i.e. the Hessian), then it is easy to distinguish minima from saddle points (the Hessian is PSD for minima). However, it is usually too expensive to calculate the Hessian.
What you might hope is that the saddle points in the problem are somewhat well-behaved: there exists (at least) one direction such that the gradient is pretty steep. This way, if you can perturb your gradient, then hopefully you’ll accidentally end up in that direction that lets you escape it.
That’s where noisy gradient descent (NGD) comes into play. This is actually a little different to stochastic gradient descent, which is noisy, but that noise is a function of the data. What we want is actually to perturb the gradient itself, so you just add a noise vector with mean 0. This allows the algorithm to effectively explore all directions.4 In subsequent work, it has been established that gradient descent can still escape saddle points, but asymptotically, and take exponential time. On the other hand, NGD can solve it in polynomial time.
What they show is that NGD is able to escape those saddle points, as they eventually find that escape direction. However, the addition of the noise might have problems with actual minima, since it might perturb the updates sufficiently to push it out of the minima. Thankfully, they show that this isn’t the case. Intuitively, this feels like it shouldn’t be that hard – if you imagine a marble on these surfaces, then it feels like it should be pretty easy to perturb oneself to escape the saddles, while it seems fairly difficult to get out of those wells.
Proof technique: replace \(f\) by its second-order taylor expansion \(\hat{f}\) around \(x\), allowing you to work with the Hessian directly. Show that function value drops with NGD, and then show that things don’t change if you go back to \(f\). In order for this to hold, you need the Hessian to be sufficiently smooth; known as the Lipschitz Hessian condition.
It turns out that it is relatively straightforward to extend this to a constrained optimization problem (since you can just write the Lagrangian form which becomes unconstrained). Then you need to consider the tangent and normal space of this constrain set. The algorithm is basically projected noisy gradient descent (simply project onto the constraint set after each gradient update).
The Unreasonable Effectiveness of Adam
Intuition about Adam / History
We talk about gradient descent (GD), which is a first-order approximation (via Taylor expansion) of minimizing some loss, and Newton’s method (NM) is the second-order version. The key difference is in the step-size, which, in the second-order case, is actually the inverse Hessian (think curvature).
Nesterov comes along, wonders if the GD is optimal. Turns out that if you make use of past gradients via momentum, then you can get better convergence (for convex problems). This is basically like memory.
What remains is still the step-size, which needs to pre-determined. Wouldn’t it be nice to have an adaptive step-size? That’s where AdaGrad enters the picture, and basically uses the inverse of the mean of the square of the past gradients as a proxy for step-size. The problem is that it treats the first gradient equally to the most recent one, which seems unfair. RMSProp makes the adjustment by having it be exponentially weighted, so that more recent gradients are preferentially weighted.
Adam (Kingma and Ba 2015Kingma, Diederik P, and Jimmy Lei Ba. 2015. “Adam: A method for stochastic optimization.” In 3rd International Conference on Learning Representations, Iclr 2015 - Conference Track Proceedings. University of Toronto, Toronto, Canada.) is basically a combination of these two ideas: momentum and adaptive step-size, plus a bias correction term.1 I didn’t think much of the bias correction, but supposedly it’s a pretty big deal in practice. One of its key properties is that it is scale-invariant, meaning that if you multiply all the gradients by some constant, it won’t change the gradient/movement.
One interpretation proffered in the paper is that it’s like a signal-to-noise ratio: you have the first moment against the raw (uncentered) second moment. Essentially, the direction of movement is a normalized average of past gradients, in such a way that the more variability in your gradient estimates, the more uncertain the algorithm is, and so the smaller the step size.
In any case, this damn thing works amazingly well in practice. The thing is that we just don’t really understand too much about why it does so well. You have a convergence result in the original paper, but I’m no longer that interested in convergence results. I want to know about #implicit_regularization.
Adam + Ratio
Let’s consider a simple test-bed to hopefully elicit some insight. In the context of the [[project-penalty]]: we want to understand why Adam + our penalty is able to recover the matrix. In our paper, we analyze the gradient of the ratio penalty, and give some heuristics for why it might be better than just the nuclear norm. However, all this analysis breaks down when you move to Adam, because the squared gradient term is applied element-wise.
This is why (Arora et al. 2019Arora, Sanjeev, Nadav Cohen, Wei Hu, and Yuping Luo. 2019. “Implicit Regularization in Deep Matrix Factorization.” arXiv.org, May. http://arxiv.org/abs/1905.13655v3.) work with gradient descent: things behave nicely and you are able to deal with the singular values directly, and everything becomes a matrix operation. It is only natural to try to extend this to Adam, except my feeling is that you can’t really do that. Since we’re now perturbing things element-wise, this basically breaks all the nice linear structure. That doesn’t mean everything breaks down, but simply we can’t resort to a concatenation of simple linear operations.2 Though, as we’ll see below, breaking the linear structure might be why it’s good.
It’s almost like there are two invariances going on: one keeps the observed entries invariant, while the other keeps the singular vectors invariant.
One conjecture as to why Adam might be better is: due to the adaptive learning rate, what it’s actually doing is also relaxing the column space invariance. But this is really just to explain why GD and even momentum are unable to succeed.
A more concrete conjecture: what we’re mimicking is some form of alternating minimization procedure. It would be great if we could show that we’re basically moving around, reducing the rank of the matrix slowly, while staying in the vicinity of the constraint set.
Intuition
Let’s start with some intuition before diving into some theoretical justifications. If we take the extreme case of the solution path having to be exactly in our constraint set, then we’d be doomed. But at the same time, there’s really not much point in your venturing too far away from this set. So perhaps what’s going on is that you’ve relaxed your set (a little like the noisy case), and you can now travel within this expanded set of matrices. Or, it’s more like you’re travelling in and out of this set. I think either way is a close enough approximation of what’s going on, and so it really depends on which provides a good theoretical testbed.
Now, in both our penalty and the standard nuclear norm penalty, the gradients lie in the span of \(W\), which highly restricts the movement direction. One might be able to show that if one were to be constrained as above, and only be able to move within the span, then this does not give enough flexibility. Part of the point is that span of the initial \(W\) with the zero entries is clearly far from the ground truth, so you really want to get away from that span.
Generalizability
One of the problems here is that matrix completion is a simple but also fairly artificial setting. One might ask how generalizable the things we learn in this context are to the wider setting. For one thing, it’s very unusual that you can essentially initialize by essentially fitting the training data exactly, though it turns out that this is okay here. This probably breaks down once you move to noisy matrix completion, but it’s unclear if there’s just a simple fix for that.
Secondly, matrix completion is a linear problem, and a lot of the reasons why the standard things might be failing is because they don’t break the linearity. But once you move to a non-linear setting, then we might be equal footing to everything else. For instance, even when we start overparameterizing (DLNN) the linearity also breaks down, freeing gradient descent from the span of \(W\).
Backlinks
- [[implicit-regularization]]
- I really think that one of the lessons of deep learning is the [[the-unreasonable-effectiveness-of-adam]] (or normalization). That is, you should always pick normalized terms over convex terms, because convexity is overrated.
Matrix Factorization to Linear Model
Two to One
One of the reasons we never tried going to depth-1 for the [[project-penalty]] was that it felt like it would be an impossible task. In particular, one of the advantages of depth 2 is that you are explicitly finding a decomposition of the matrix into two matrices. It felt like therefore you needed at least depth-2 to get something interesting, as that structure would be forced.
If you have a depth-1 matrix, then you’re not assuming that it can be decomposed, and perhaps it actually can’t be decomposed into something nice. Thankfully matrix completion really only cares about predicting the unobserved entries, which ultimately is the same thing.
And of course, it turns out that we don’t actually need that structure, and, in fact, it might be a hindrance to the success of the algorithm. This definitely feels counter-intuitive at face value. We know that there is some structure, so it really should benefit us to enforce that, otherwise your algorithm doesn’t know what it should be looking for. Some possible reasons:
- if you force this structure, then you’re also forcing the path of the solutions to also to be thusly decomposable, which might be sub-optimal.
- I don’t know. This feels mysterious. Should be added to [[next-steps-for-penalty-paper]].
Update: following on from [[experimental-logs-for-matrix-completion]], we have looked at how the nuclear norm fails in the depth-1 case, which is that you dampen the top singular values and reconstruct the residuals from small singular vectors (feels ever so slightly like [[benign-overfitting-in-linear-regression]]).
Don’t forget that actually from SVD you can always just decompose it into two matrices, so the range of the two models are the same (excluding the cases where one of the matrices is just the identity). So really what’s it doing is changing the gradient trajectory.
Next Steps for Penalty Paper
- Matrix Completion -> ?
Our procedure works so well for matrix completion. However, how dependent is it to our data generating process? Matrix completion is basically a different view of link prediction – I wonder how well it does in that setting?
Can we use this in other settings: collaborative filtering, noisy matrix completion, network analysis.
- Speed/Initialization
This thing is pretty slow, especially compared to the more direct approaches. Is it possible to take what we’ve learnt from this method and apply it to other methods and get state-of-the-art and very high speed?
The nice thing now is that we really don’t have to worry about speed since we’re mostly just interested in implicit regularization in deep learning
- Theory
It would be really nice to be able to do some theory here. The main problem is that the theory for Adam is pretty unwieldy. It’s an element-wise calculation, and so it’s not particularly amenable to study through matrix calculations (the Hadamard doesn’t really help here).
- Noisy Matrix Completion
This is more in the realm of statistics, and, as such, usually requires considerable theory (though we can always the help of our collegues). It looks like our algorithm isn’t that great in the noisy case, as it’s esentially assuming that the data is noise-less. If we alter the loss function to be truncated, what happens then? Can we better handle the noisy case?
- Collaborative Filtering
The most important use-case for matrix completion is collaborative filtering. Except there it’s not as exact as saying that the matrix is low-rank. You’re instead looking for features, and some looser form of sparsity. I suspect our algorithm relies on the nice structure of matrices a little too much to be that useful in collaborative filtering, though, my intuition could be misguided here. Might even be able to do this with dictionary learning (see https://arxiv.org/pdf/1905.12091.pdf).
- More General Setting
See [[extending-the-penalty]].
Backlinks
- [[matrix-factorization-to-linear-model]]
- I don’t know. This feels mysterious. Should be added to [[next-steps-for-penalty-paper]].
Project Penalty
(Just submitted this to NeurIPS.)
- In trying to understand why deep learning works so well, what we’ve come to realize is that gradient descent, which seems to be incredibly simple, actually ends up doing a lot of things in the background.
- For instance, under certain specific regimes, gradient descent converges to the minimum Frobenius norm solution.1 Least squares problem using a linear model (i.e. depth-1 neural network).
- This is basically the idea of implicit regularization. In particular, we’re interested in what kinds of biases are induced by combination of the parameterization and the optimization chosen.
- Recently, it was conjectured (Gunasekar et al. 2017Gunasekar, Suriya, Blake Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nathan Srebro. 2017. “Implicit regularization in matrix factorization.” In Advances in Neural Information Processing Systems, 6152–60. TTI, Chicago, United States.) that for the problem of matrix completion, a 2-layer linear neural network trained using gradient descent converges to the minimum nuclear norm solution.
- More recently, this conjecture was disputed (Arora et al. 2019Arora, Sanjeev, Nadav Cohen, Wei Hu, and Yuping Luo. 2019. “Implicit Regularization in Deep Matrix Factorization.” arXiv.org, May. http://arxiv.org/abs/1905.13655v3.), who show that if you move to depth-3 (and higher2 In theory, things should get better with depth. In practice, going to depth-3 is sufficient, and things get a little weird if you increase the depth too much.) then it actually does better than the nuclear norm.
- You have to be in a data-poor regime, where the minimum nuclear norm and the minimum rank solution don’t coincide, otherwise you’re potentially conflating things.
- To summarize, they find that depth is doing this really interesting thing in the linear neural network setting, whereby it’s biasing towards low-rank solutions/parameters.
- Further, they conjecture that this effect cannot be captured by a simple penalty (given that the nuclear norm doesn’t work).
- As it turns out, there is an explicit penalty. And it’s given by the ratio of the nuclear norm and the Frobenius norm (see [[effectiveness-of-normalized-quantities]]).
- But there’s a second piece to this puzzle. A recent result (Arora, Cohen, and Hazan 2018Arora, Sanjeev, Nadav Cohen, and Elad Hazan. 2018. “On the optimization of deep networks: Implicit acceleration by overparameterization.” In 35th International Conference on Machine Learning, Icml 2018, 372–89. Institute for Advanced Studies, Princeton, United States.) showed that the effect of depth is also to something akin to an accelerated gradient method. That is, it has memory of past gradients, and uses that to its advantage. They spectulated again that this is distinct from explicit accelerators.
- As it turns out, we suspect it is very similar to Adam, the go-to optimizer in deep learning.
- Let’s recap: these two papers above have found really interesting implicit biases that depth (or over-parameterization) is achieving. And importantly, they think these things are unique to implicit regularization – that they can’t just be replaced with some explicit form, which explains why deep learning does so well generally.
- What we find is that, actually, in this context, you can indeed do exactly that. You can find explicit forms for the effects of depth! How can we tell?
- Let’s just start by getting rid of depth, and consider a linear model that we’re going to train with gradient methods (starting with gradient descent).
- If you add our penalty, absolutely nothing happens. It’s a little disheartening actually.
- However, if you replace the optimization with Adam, then all of a sudden, magic happens. It’s really quite magical. In particular, this obtains state-of-the-art performance.
- A debate I had with my collaborator on this is how to interpret these results once you include depth. My contention is that if you then add depth into the picture, then you can’t really say that you’ve captured depth, because now these two effects are interacting. Also, just because you capture something, this might not be an idempotent function!3 In other words, the effect of depth is not like a projection: applying depth twice is not the same as applying it once. When we talk about things being orthogonal to one another, we might inadvertently think everything is linear and therefore idempotent. In any case, what we find is that generally speaking if you add depth, things change, which is unsurprising.
- What this suggests to us is that actually, what depth is doing is some combination of rank-reduction that can be cleanly captured by our penalty, and something like Adam (definitely not orthogonal to it).
- Indeed, the fact that our model outperforms that of deep matrix factorization suggests that any orthogonal component is actually hurtful!
- While it seems like this isn’t that strong of a result: we haven’t proven any form of equivalence, I think that’s actually the wrong way to think about it: there is most likely not going to be anything that can exactly replicate the effect of depth. What we’re learning is that over-parameterization is a fairly complicated beast, and since it’s implicit, it’s very difficult to pin down. We can look at things like the singular values, and try to model their dynamics, but that’s still not enough to explain the discrepancy.
- The nice thing about matrix completion is that it’s a very simple setting, and the generalization performance varies quite drastically across methods, so you can use that to guide intuition about which biases are actually helpful.
- There is oftentimes beauty and truth in simple ideas. The fact that only in the intersection of our penalty and that of Adam do things happen, and the simplicity of this model, gives me confidence that there is something fundamental at play here, definitely for the problem of matrix completion, but hopefully more generally speaking too.
- Is it the case that if we replace our regularizers with normalized versions, then all of a sudden we’re going to get even better performance?
Backlinks
- [[master-paper-list]]
- [[project-penalty]]
- [[matrix-factorization-to-linear-model]]
- One of the reasons we never tried going to depth-1 for the [[project-penalty]] was that it felt like it would be an impossible task. In particular, one of the advantages of depth 2 is that you are explicitly finding a decomposition of the matrix into two matrices. It felt like therefore you needed at least depth-2 to get something interesting, as that structure would be forced.
- [[discretization-of-gradient-flow]]
- Finally, in relation to the [[project-penalty]], this doesn’t actually work for things like Adam, which we know to be amazing in practice. So, it seems like there’s still work left to understand why on earth the adaptive learning rates work so well.
- [[the-unreasonable-effectiveness-of-adam]]
- Let’s consider a simple test-bed to hopefully elicit some insight. In the context of the [[project-penalty]]: we want to understand why Adam + our penalty is able to recover the matrix. In our paper, we analyze the gradient of the ratio penalty, and give some heuristics for why it might be better than just the nuclear norm. However, all this analysis breaks down when you move to Adam, because the squared gradient term is applied element-wise.
- [[implicit-regularization]]
- In fact, that’s exactly the hope that [[project-penalty]] provides: in a very simple example, we see that we can replace implicit by explicit, to great effect.
Matrix Completion Experiments
For posterity, we leave some of our experiments up.
Comparison of various matrix completion methods, in the noise-less case. I did 5 repeats, so the first graph is with all repeats, while the second graph is mean-collapsed. The Convex Program actually does really well (it’s just slow, probably at the same order as our LNN).
library(ggplot2)
x <- read.csv("20-05-17 comparison.csv")
ggplot(x, aes(x=sample_size, y=Loss.test, group=method)) + geom_point() + geom_smooth() + scale_y_log10() + facet_grid(.~method)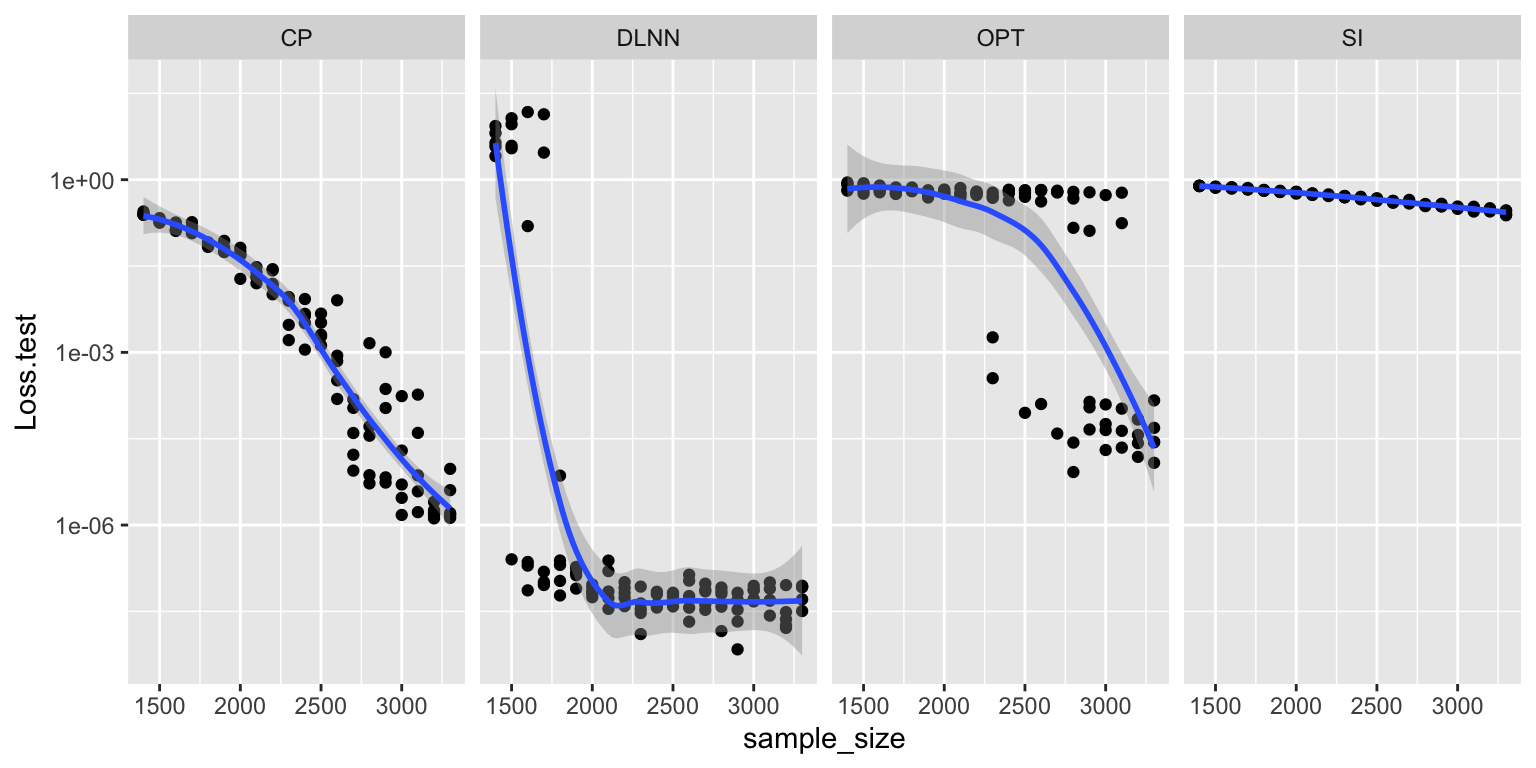
y <- aggregate(x$Loss.test, list(sample_size=x$sample_size, method=x$method), mean)
ggplot(y, aes(x=sample_size, y=x, color=method)) +
geom_point() +
geom_line() +
scale_y_log10() +
# geom_smooth(method = lm, formula = y ~ splines::bs(x, 3), se = FALSE) +
ylab("test loss")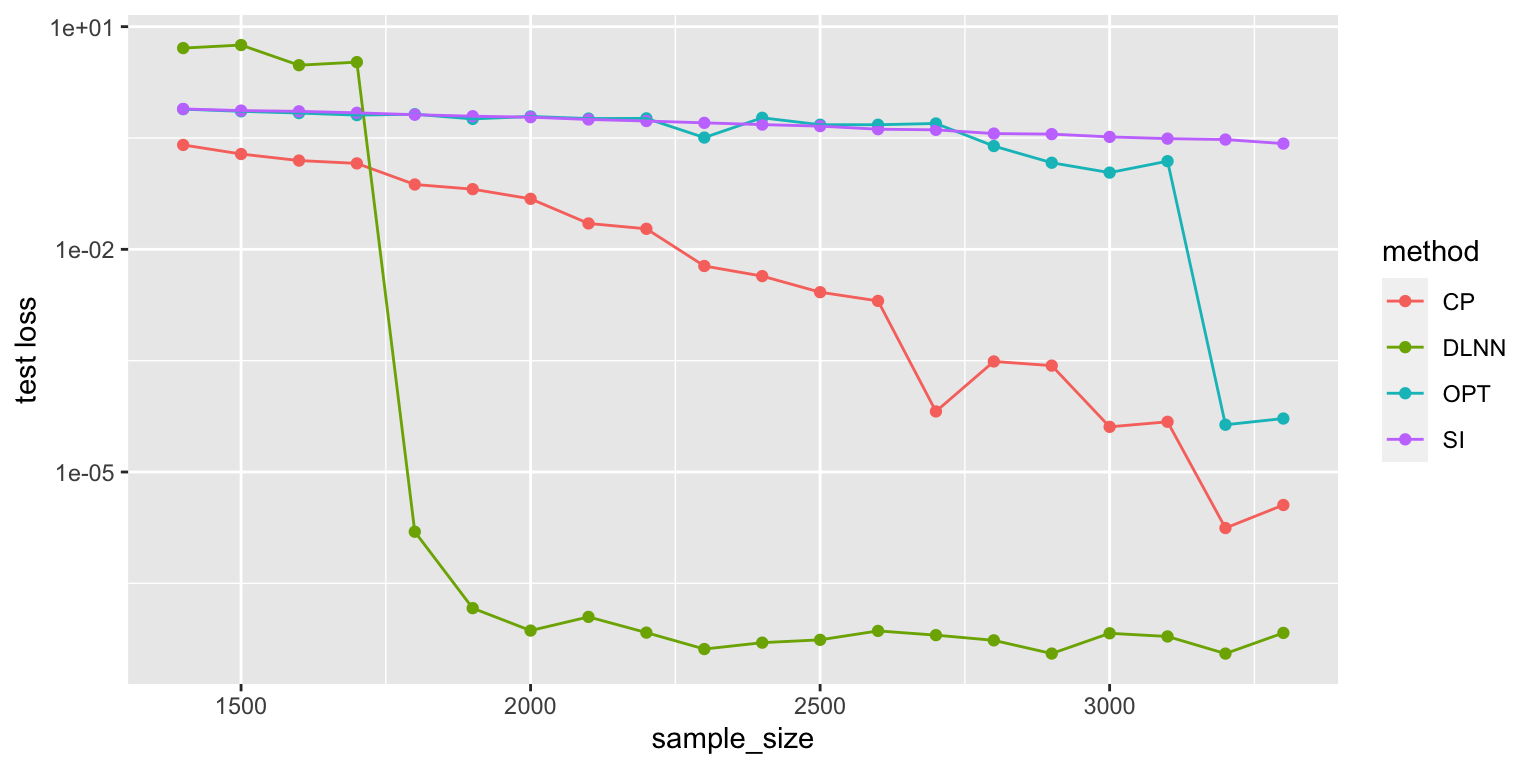
Adding Noise
The curious thing is that, things become much more equal when you introduce noise.
x <- read.csv("comparison2.csv")
x[x$method=="DLNN", "method"] = "Adam:2 (ratio)"
z <- read.csv("20-05-18 comparison.csv")
z$method <- ifelse(z$optim=="Adam", "Adam:4 (ratio)", "GD:4 (ratio)")
z2 <- read.csv("20-05-19 comparison.csv")
z2$method <- ifelse(z2$reg_norm=="ratio", "GD:4 (n/a)", "GD:4 (nuc)")
z <- z[,names(x)]
z2 <- z2[,names(x)]
x <- rbind(x,z,z2)
y <- aggregate(x$Loss.test, list(sample_size=x$sample_size, method=x$method, noise=x$noise), mean)
ggplot(y, aes(x=sample_size, y=x, color=method)) + geom_line() + scale_y_log10() + facet_grid(.~noise) + ylab("test loss")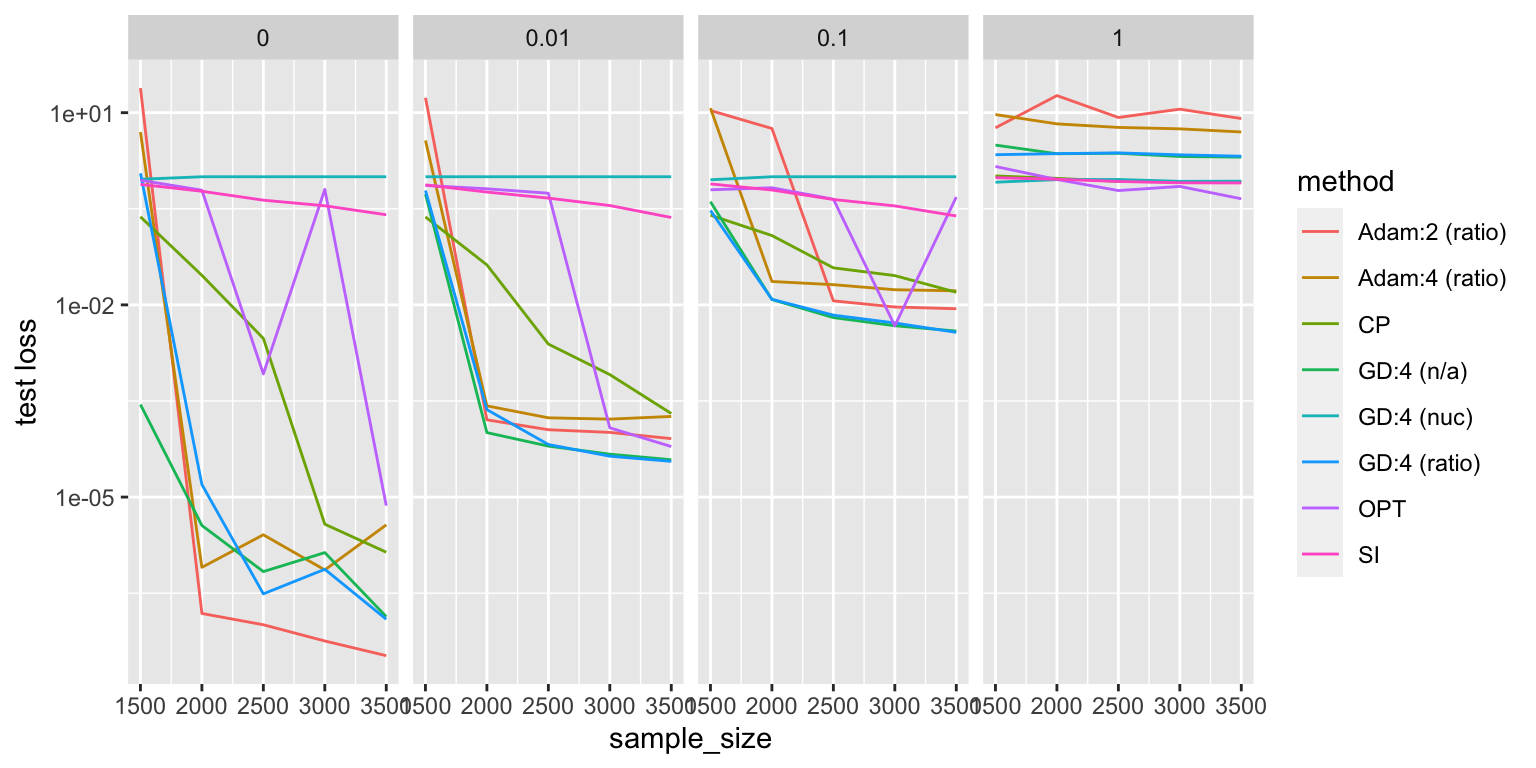
- gradient descent with or without the penalty does really well, especially with a little bit of noise
- interestingly, things reverse with enough noise. in the panel where \(\sigma = 1\), all the neural network methods are dominated by the other methods
- at zero noise, things are the opposite
- with nuclear penalty, everything is just terrible
- curious: it looks like there’s almost a phase transition in sample size for Adam. maybe it just needs more sample size to get to the same rate.
Remarks:
- it feels like noise is somehow equalizing the playing field. put another way, it’s sort of masking the problem at hand.
- there’s the recovery of the low-rank matrix from the observations, and then there’s figuring out, accounting for noise, which low-rank matrix in the vicinity should you choose.
- this relates (nicely) to [[project-interpolation]]. here, we are dealing with depth of 2, and so one could argue that we’re in the regime where we’re just able to interpolate, but not well enough, so you can’t get nice generalization.
- but it feels like matrix completion is a very particular problem, and since we’re restricting ourselves to just linear neural networks, I don’t expect to see the same kind of double-dipping behaviour.
- if we relax the loss function (have it within \(\delta\)), we should be able to get competitive rates in the noisy case? [[idea]]
Update
For some reason, we never tried depth 1!
z3 <- read.csv("20-05-20 comparison.csv")
z3$method <- ifelse(z3$optim=="Adam", "Adam:1 (ratio)", "GD:1 (ratio)")
z3 <- z3[,names(x)]
x <- rbind(x,z3)
y <- aggregate(x$Loss.test, list(sample_size=x$sample_size, method=x$method, noise=x$noise), mean)
y <- y[stringr::str_detect(y$method, "\\("),]
y <- y[!stringr::str_detect(y$method, "(nuc|n/a)"),]
y$GD <- stringr::str_detect(y$method, "GD")
ggplot(y, aes(x=sample_size, y=x, color=method)) + geom_line(aes(linetype=GD)) + scale_y_log10() + facet_grid(.~noise) + ylab("test loss")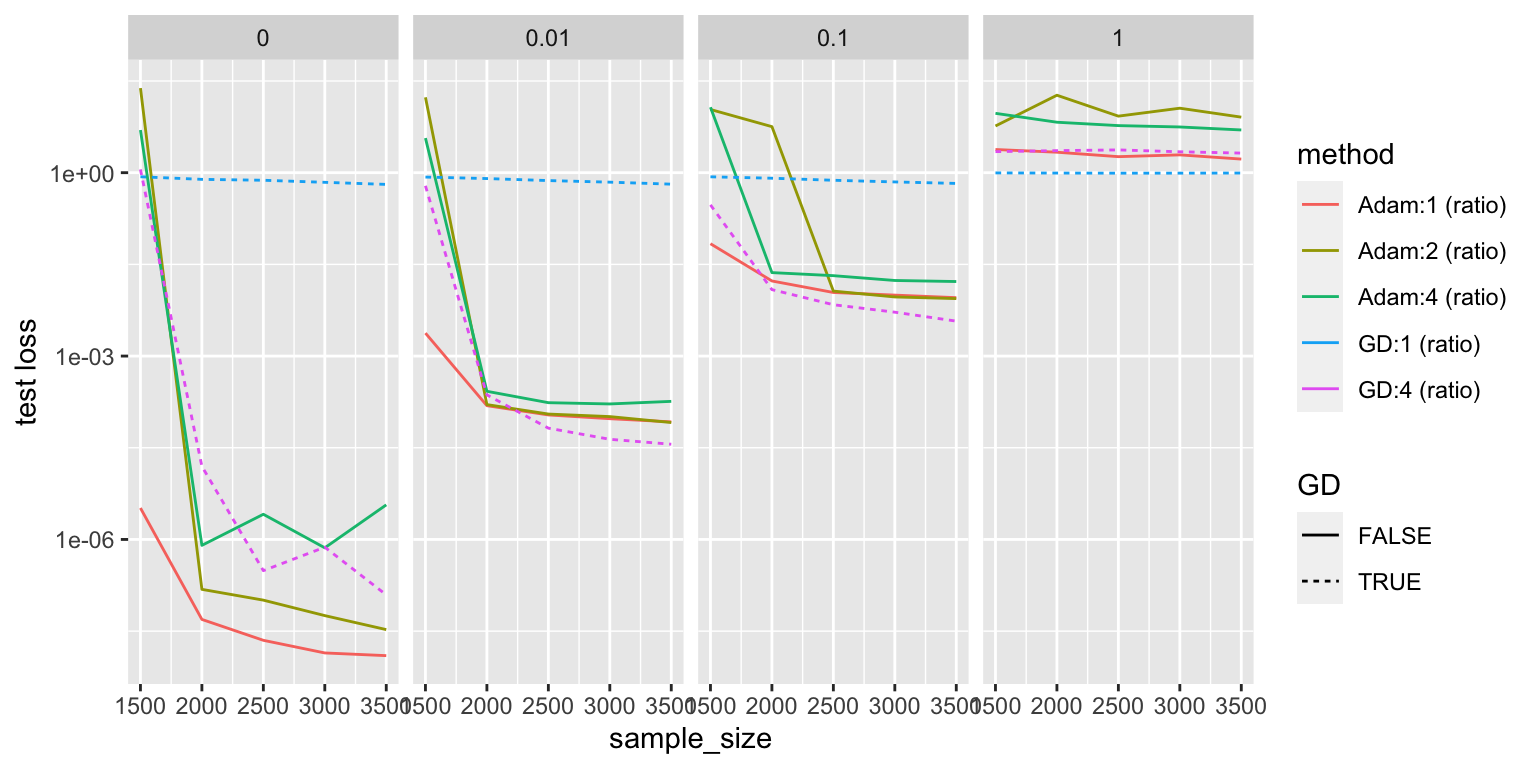
It looks like depth 1 Adam is the king!
Extending the Penalty
Question: how to extend the \(L_1/L_2\) ratio penalty to more general settings?
- currently, in the case of matrix completion, the penalty is straightforward, since we have a product matrix already as our final goal [[the-form-of-the-loss-in-matrix-completion]].
- in more general (or typical) settings, you have the weight matrices (plus bias vectors),
- currently, you can add penalties to the weight matrices themselves, but this seems a little crude
- the parallel for our matrix completion problem would be if we did it for the individual matrices, not the full product matrix (which doesn’t seem that great)
- let’s take a step back here:
- I feel like you can ask the same question about (Arora et al. 2019Arora, Sanjeev, Nadav Cohen, Wei Hu, and Yuping Luo. 2019. “Implicit Regularization in Deep Matrix Factorization.” arXiv.org, May. http://arxiv.org/abs/1905.13655v3.). that is, they want to say something about how depth is playing this interesting role where it’s dampening the singular values, or simply making it more sparse
- but if you were to generalize this, then it’s unclear what singular values you’re talking about?1 In fact, this is probably why they don’t actually generalize. A worry I have is that all this work using matrix completion as the test-bed might not be applicable anywhere else.
- and whatever singular values you want to talk about, well then there’s a matrix, and viola, we can simply just add the regularizer to that matrix, and the equivalence follows
- this is a similar problem to what we had when we wanted to have the trivial extension of the matrix completion problem to allow for deep non-linear networks as opposed to DLNNs.
- there, we simply added back the non-linear transforms between the weights.
- we found that it didn’t really do much in terms of test performance
- seems like, because the problem is linear to begin with, having non-linearities introduced doesn’t really give you any gains.
- very recently, a group (Yang, Wen, and Li 2019Yang, Huanrui, Wei Wen, and Hai Li. 2019. “DeepHoyer: Learning Sparser Neural Network with Differentiable Scale-Invariant Sparsity Measures.” arXiv.org, August. http://arxiv.org/abs/1908.09979v2.) used a variant of our penalty to sparsify matrices. it’s not quite what we’re interested in – they basically show that using \(l_1/l_2\) versus just a uniform \(l_1\) penalty on the weights does better at sparsifying.
Backlinks
- [[next-steps-for-penalty-paper]]
- See [[extending-the-penalty]].
Effectiveness of Normalized Quantities
In the context of matrix completion, it is known that the nuclear norm, being a convex relaxation of the rank,1 You can think of these as the matrix version of the \(l_1\) to \(l_0\) duality. has very nice low-rank recovery properties. However, in sparser regimes (not enough observed entries), the nuclear norm starts to falter. This is because there is sufficient ambiguity (equivalently, not enough constraints on the convex program).2 Recall that the convex program is something like \(\min \norm{W}_{\star} \text{ s.t. } P_{\Omega}(W^\star) = P_{\Omega}(W)\), where the \(P_{\Omega}\) is the convenient operator to extract the observed entries Thus, minimizing the nuclear norm doesn’t actually recover the true matrix.
However, it turns out that simply normalizing it works wonders. Consider the penalty, \(L_{\star/F}\), which is given by
\[ \begin{align*} \frac{L_1}{L_2} = \frac{ \sum \sigma_i }{ \sqrt{ \sum \sigma_i^2 } }, \end{align*} \]
where \(\sigma_i\) are the singular values. The idea here is that we’re interested in the relative size of our singular values, not the absolute sizes. Using the nuclear norm as a penalty means that you can simply push down all the entries of your matrix to.
Compare this to the gradient accelerator ADAM, which, in a nutshell considers a normalized gradient sequence. That is, the update step is given by3 Granted, I am hiding some details, like how the summation is actually weighted to prioritize the most recent gradient, the division is element-wise, plus some computation tricks to ensure no division by zero.
\[ \begin{align*} \frac{ \sum g_t }{\sqrt{\sum g_t^2}}, \end{align*} \]
Remark. Experiments show that it is the denominator that is more important than the numerator. So, really, what seems to be important is that you’re normalizing each gradient parameter by the magnitude of the gradient. I feel like there’s something statistical about all this that we might be able to learn.
I tried to do something about the Hadamard product, but my feeling is that this cannot be captured through matrix operations alone.where \(g_t\) is the gradients of the loss. The reason I bring up these two quantities is that it turns out that only by using these two methods do we get something interesting coming out. It could very well be coincidence that they have a similar form, but I suspect that perhaps normalized quantities are somehow superior in the deep learning regime.
Parallels
Originally I thought this felt a lot like our scores in #statistics, but upon further inspection I realized that this would only hold if you have assume zero mean, since the entries aren’t actually centered (and no \(\sqrt{n}\)). The problem there is that all the singular values are positive, so it seems sort of weird to say that this is essentially a \(Z\)-score of the null hypothesis that these were drawn from a zero-mean normal distribution.
Backlinks
- [[project-penalty]]
- As it turns out, there is an explicit penalty. And it’s given by the ratio of the nuclear norm and the Frobenius norm (see [[effectiveness-of-normalized-quantities]]).
- [[exponential-learning-rates]]
- Two key properties of SOTA nets: normalization of parameters within layers (Batch Norm); and weight decay (i.e \(l_2\) regularizer). For some reason I never thought of BN as falling in the category of normalizations, ala [[effectiveness-of-normalized-quantities]].
- [[fractals]] Scale-free, or scale-invariance. If you’re given a picture of some rock, then you can’t tell what scale it is at, since you have self-similarity across scaling. Hence you need that reference scale on the bottom right. I wonder if this relates to scale-invariance (à la [[effectiveness-of-normalized-quantities]]).