#psychology
Multidimensional Mental Representations of Natural Objects
src: (Hebart et al. 2020Hebart, Martin N, Charles Y Zheng, Francisco Pereira, and Chris I Baker. 2020. “Revealing the multidimensional mental representations of natural objects underlying human similarity judgements.” Nature Human Behaviour 4 (11): 1173–85.), and an earlier version in ICLR.
Contemplations
Distributed Representation
Figure 1: General Workflow
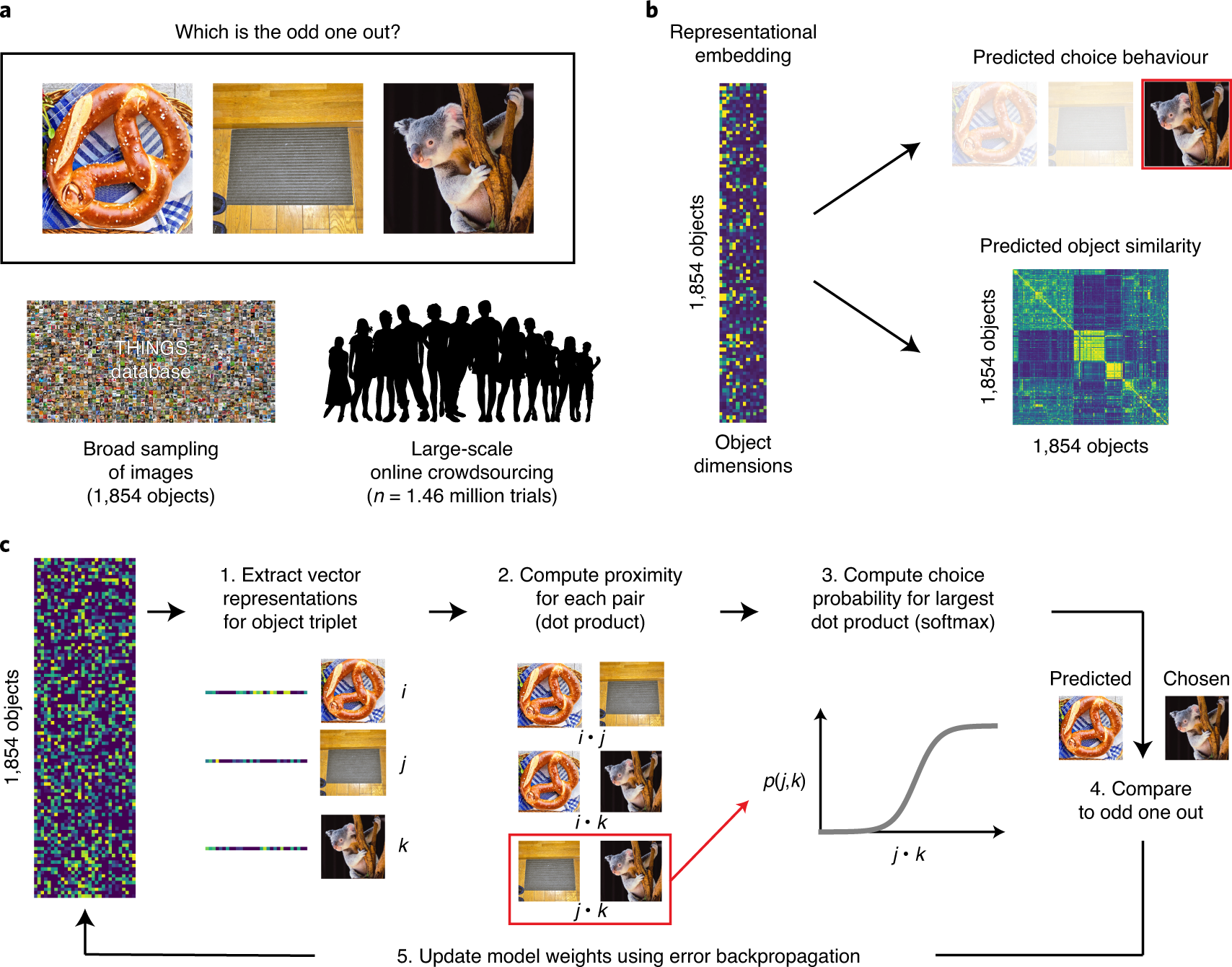
The idea of “distributed representation” (word2vec) is that a) words are represented as high-dimensional vectors, and b) words that cooccur should be closer together. What this means is that you can simply ingest a large corpus of unstructured text, collecting co-occurrence data, and learning a distributed representation along the way. The beautiful thing about this approach is that the only thing it relies on is some notion of co-occurrence; in the case of language, this is simply a window function.
What happens when you don’t have such information? Well then, you have to get a little creative. For those familiar with word2vec, you’ll know that a lesser-known but powerful trick they proposed is this notion of negative sampling: they found that it wasn’t enough to, during the traversal of your corpus and training your model, to push co-occurring words together, but it was also important to push words apart (i.e. randomly pick a word, and then do the opposite manoeuvre). Note the similarity to [[triplet-loss]]. In essense, we can move from pairs to triplets. But this seems like we’ve made the problem even more difficult.
As it turns out, the triplet structure allows us do something interesting, which is to turn the problem into an “odd-one-out” task. Cute!1 Dwelling on this a little longer, the paired version would be more like, show pairs to people and ask if they should be paired, which feels like an arbitrary task. The alternative, which is to give a rating of the similarity, naturally inherits all the ailments that come with analyzing ratings. In other words, given a corpus of images of objects, we can show a random triplet of them to humans, and ask which one is the odd one out. All that remains is to train our models with this triplet data. Here, they adapt softmax to this problem, applying it only to the chosen pair:
\[ \begin{align*} \sum_{(i,j,k)} \log \frac{ \exp\left\{ x_i^T x_j \right\} }{ \exp\left\{ x_i^T x_j \right\} + \exp\left\{ x_i^T x_k \right\} + \exp\left\{ x_j^T x_k \right\}} + \lambda \sum_{i = 1}^{m} \norm{x_{i}}_{1}, \end{align*} \]
where the first summation is over all triplets, but, crucially, we designate \((i,j)\) to be the chosen pair (i.e. \(k\) is the odd one out). The \(l_1\) penalty induces sparsity on the vectors, which improves intrepretability. Finally, and I’m not sure exactly how they implement this, but they also enforce the weights of the vector to be positive, to provide an additional modicum of interpretability.2 I feel like they overemphasize these two points, sparsity and positivity, as a way to differentiate themselves from other methods, when it’s really quite the trivial change from a technical perspective.
Figure 2: Interpretable dimensions
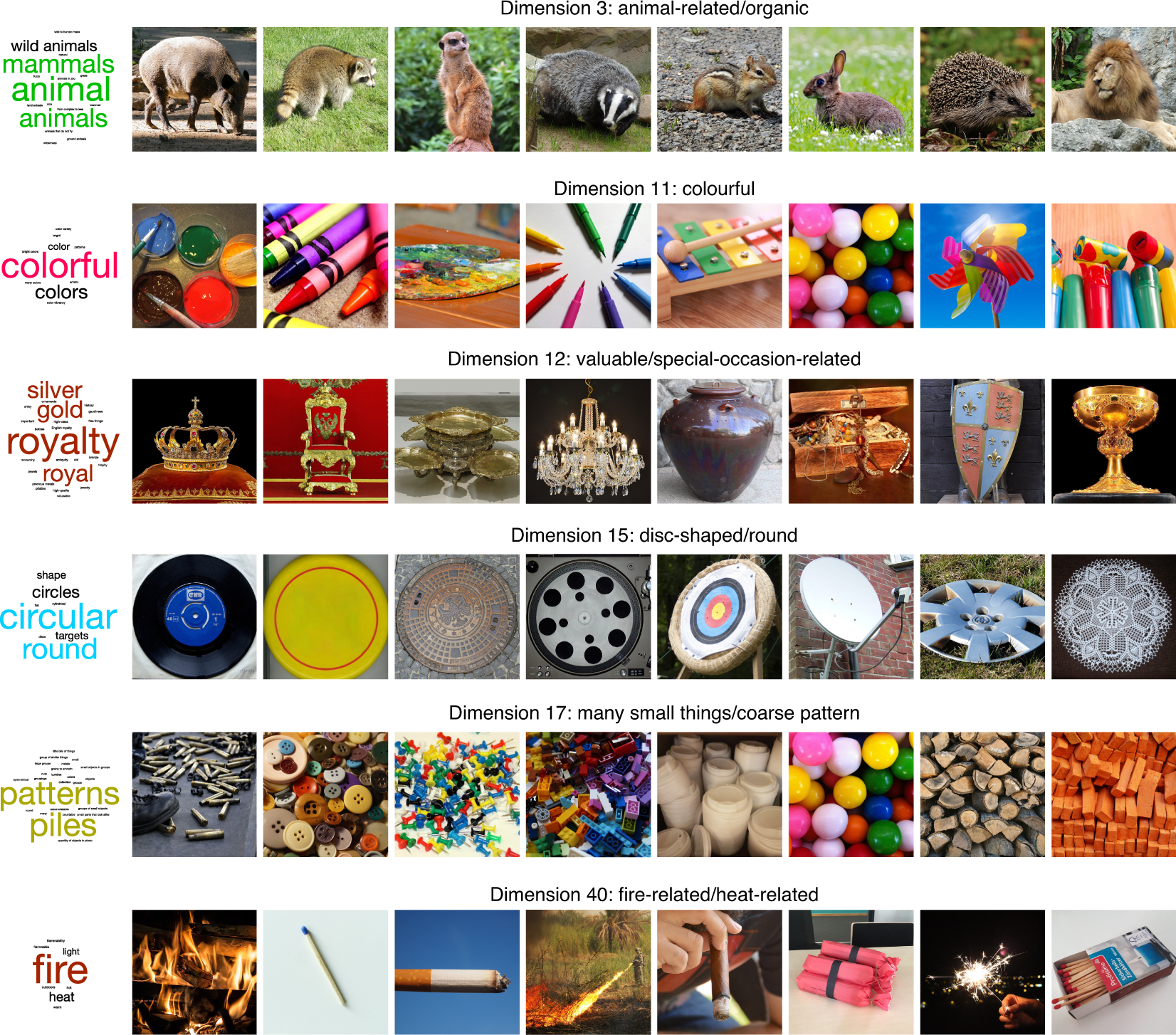
What is the output of this model? Ostensibly, it is a “distributed representation” of how we as humans organize our understanding of objects, albeit also conflating the particulars of the image used to represent this object.3 Does the prompt ask the subject to consider the image as an archetype, or simply ask to compare the three images on face value, whatever they see fit? My guess is probably the latter. Note that even though we’re dealing with the visual domain, the open-endedness of the task means that humans aren’t necessarily just using visual cues for comparison, but might also be utilizing higher order notions.
A crude approximation is that this model outputs two types of features: visual properties, like size, texture, etc.; and then the more holistic, higher-order properties, such as usage, value/price, etc. The key is that the latter property should not be able to be inferred from visuals alone.4 So really what I’m saying is that there are two groups, \(V\) and \(V^C\). Not groundbreaking. Thus, this model is picking something intangible that you cannot possibly learn from simply analyzing image classification models. However, this then begs the question: is it possible to learn a similar model by considering a combination of images (visual features) as well as text (holistic features)? What would be the nature of such a multi-modal learning model?
I see a few immediate challenges. The first is that, while one could take the particular image chosen in this experiment to represent an object, it would be too specific. What we would want is to be able to learn a single feature across all images of a single object. I feel like this should be something people have thought about, right? The second problem is, are word embedding of the objects sufficient to get the higher-order features? Supposing we solve all those problems, we’re still left with the question of how to combine these two things meaningfully. It feels to me like we should be training these things in unison?
Typicality
The idea here is that the magnitude of a particular dimension should import some meaning, the most likely being the typicality of this object to this particular feature (e.g. food-related). What they do is pick 17 broad categories (the graphs in Figure 3) that have a corresponding dimension in the vector representation, then for each image/object in this category (e.g. there are 19 images in the Drink category, corresponding to 19 points on the graph), they get humans to rate the typicality of that image for that category.
Figure 3: Typicality Scores
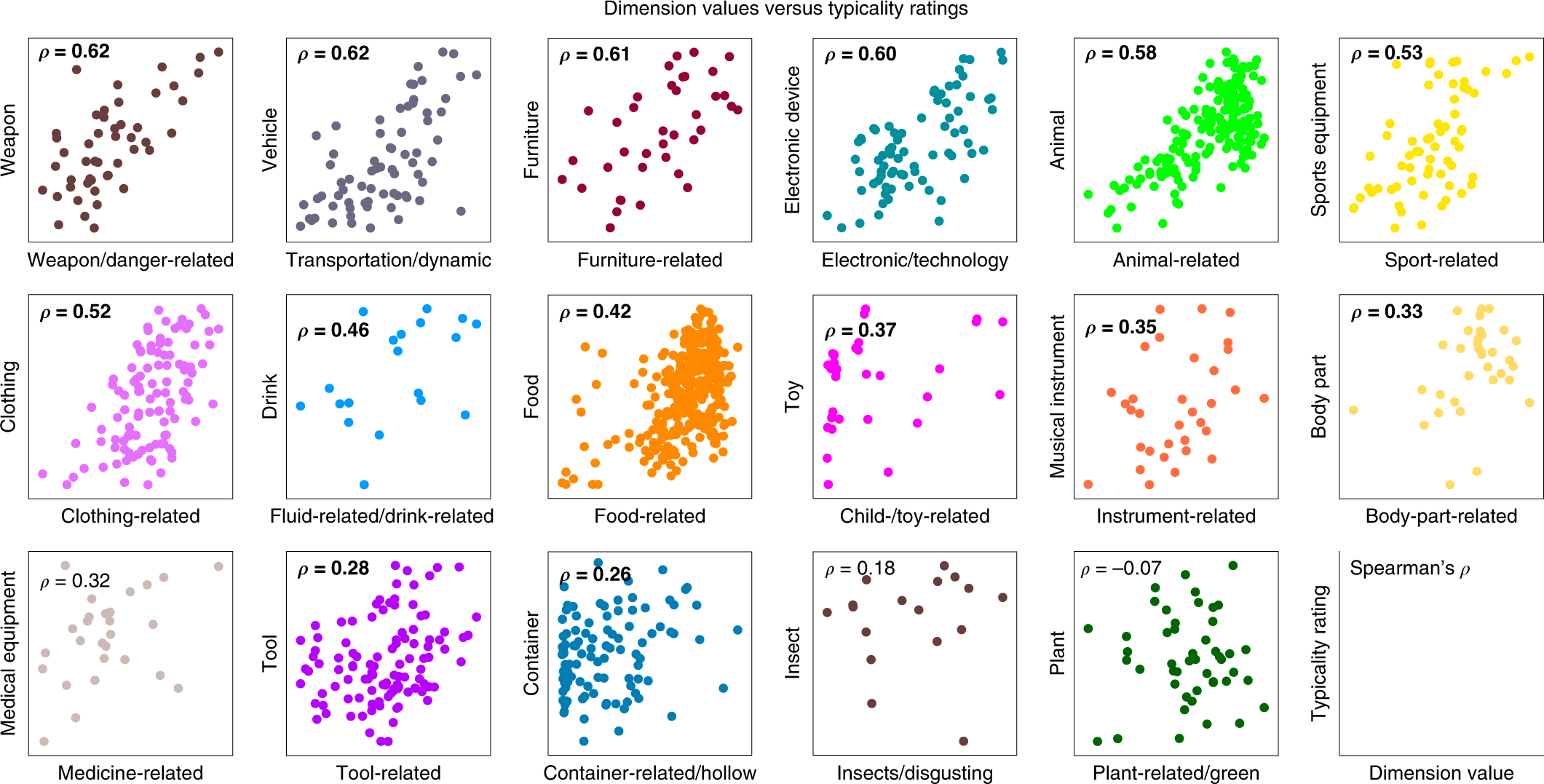
This result is somewhat surprising to me. For one, if you give me a list of images for, say, the category of animals, I would have no idea how to rate them based on typicality. Like, I think it would involve something cultural, regarding perhaps the stereotypes of what an animal is. I can imagine there being some very crude gradation whereby there are the clear examples of atypical, and then clear examples of typical, and then the rest is just a jumble. It doesn’t really appear that way from the data – I would have to look at these images to get a better sense.5 As an aside, I wish they also included the values of all the other images too, not just those in this category. Perhaps they are all at close to zero, which would be great, but they don’t mention it, so I assume the worst.
Also, how is it able to get at typicality through this model? I think what’s illuminating to note is that, out of the 27 broad categories of images in this dataset, 17 can be found in the 49-dimensional vector representation. Here’s what I think is probably happening (in particular for these 17 categories):
- if all three images are from different categories, then probably we’re learning something about one of those other dimensions (hopefully);6 Another thing is that this step helps to situate the categories amongst each other.
- if two images are from the same category, and the third is different, then the same pair is most often picked (helping to form this particular dimension);
- if all three images are picked, then I guess the odd one out is the one that’s the least typical.
Having laid it out like so, I’m starting to get a little skeptical about the results: it almost feels like this is a little too crude, and the data is not sufficiently expressive for a model to be able to learn something that’s not just trivial. Put another way, this almost feels like a glorified way of learning the categories – though, there’s nothing necessarily wrong with that, since the (high-level) categories are obviously important.
Perhaps it helps to consider the following generative model for images: suppose each image was represented by a sparse vector of weights, with many of the coordinates corresponding to broad categories. Set it up in a such a way that if you’re in a broad category, then that dominates all other considerations (so it follows the pattern above). Then, simply run this odd-one-out task directly on these vectors, and see if you’re able to recover these vectors.7 It almost feels like a weird autoencoder architecture…
Loftus and Memory
src: New Yorker
Reading about the malleability of memory, and relating this to the recent ideas from #neuroscience on how our cells work through linear algebra (see [[rotation-dynamics-in-neurons]] and [[neural-code-for-faces]]), I wonder if there’s a similar way of coding the curious properties of memory as artefacts of linear algebra.
A few key ideas:
- I assume memory is projected information, and so reconstructing it involves remembering the correct angle
- the malleability, or degradation of memory over time might come from the fact that you’re sharing the same space, and so over time, as you write to the same space (at various angles), you’re inevitably going to get corruption
- a prediction would be that if your ability to form new memories is lost, then you’re going to get much less corruption (though basically that holds for any memory process that involves some sort of overwriting).
- It’s clear that memory and emotions are heavily intertwined, though I don’t see how this model is able to capture that
- It’s also clear that memory and stories are related:
- one way to think about this is that stories are either simple building blocks that help with prediction (i.e. if you have a story framework, then it sort of tells itself).
- so it’s sort of like having lower dimensional representations of our memories, that are able to capture the essense of the memory, without actually having to store all the particulars.
Neural Code for Faces
src: (Chang and Tsao 2017Chang, Le, and Doris Y Tsao. 2017. “The Code for Facial Identity in the Primate Brain.” Cell 169 (6): 1013–1028.e14.), Nature news feature.
- primates have special(ized) face cells for disambiguation
- these cells are found in the inferotemporal (IT) cortex
- two patches are considered: middle lateral/middle fundus (ML/MF), anterior medial (AM)
- previous work showed a hierarchical relationship (AM being downstream, possibly the “final output stage of IT face processing”)
- and \(\exists\) sparse set in AM which seemed to fire for specific individuals (independent of head orientation), suggesting it was capturing something very high-level
- question: what are the functions of these cells? one idea is that each cell encodes a particular individual1 “Jennifer Aniston” cells, after a study in epileptic patients found a cell that would only fire when presented with JA, regardless of face or just her name.
- that does not scale, obviously2 I suspect that they just didn’t have a large enough sample. actually, that’s the whole point of this article! that just because it’s only firing for one thing in your set doesn’t necessarily mean it’s unique. one caveat might be that the things that would trigger activation might not be natural (so practically it’s unique). also, it’s important to distinguish visual/face processing, which is much more low-level, than, say, high-level object recognition, maybe.
- answer: construct the following face space:
- decompose a face into two broad category of features
- shape (S): i.e. the geometry of the facial landmarks
- appearance (A): the rest (i.e. independent of shape)
- this is accomplished by morphing all faces to the same average face-shape
- from this decomposition, get 200 S and 200 A features, and perform PCA to get top 25 for each; giving, finally, a 50-d face space!
- decompose a face into two broad category of features
- result: single neurons are axis-coding (i.e. are projections in the face space)
- to test this, simply determine the vector for a cell, and see faces that lie orthogonal to that vector have the same firing:
- and crucially, they are able to determine the null space for those cells that were previously thought to be individual

- similarly, they can predict response to new faces, which they also do.
- to test this, simply determine the vector for a cell, and see faces that lie orthogonal to that vector have the same firing:
- result: ML/MF cells fired more for shape, while AM fired more for appearance
- result: ~200 face cells needed to decode human faces (and encode)
- implications:
- axis-coding, i.e. linear projections, are efficient, robust and flexible (see remark below).
- caveats:
- all faces are neutral (i.e. don’t include expressions/emotions): but that seems fair, since we’re doing facial recognition, not emotion detection
- potentially missing axes, given the training data
Thoughts:
- a point made in the paper is that this face space is rather constrained, and every point in this space is a valid/realistic face. however, that also suggests that it might be a little bit too restrictive
- they’ve appreciated that other axes could be missing
- but my worry is that, with results like “they can encode/decode faces,” the strong caveat there is: for faces falling into this particular space
- granted, it is clearly a large space, but I suspect there are probably more axes available, and by projecting, you’re missing out on other spaces perhaps.
- i.e. this is not necessarily the full picture
- a similar point is, it does feel like the features that they’ve come up with are closely related to the function of the cells, but I’m curious if a completely different encoding/feature-set would also produce the same empirical results
- for instance, as they point out in the section of reproducing these results with a CNN, one doesn’t necessarily have to morph the face to get the appearance features (as it seems biologically implausible for our brains to be morphing faces)
- and so they say you can probably get the same features by extracting information around the eyes
- but then why not just do what we think the biology is doing
- a natural follow-up question is, what is the subspace spanned by these vectors: do they complete the space?
- one would hope that the vectors themselves are orthogonal (or perhaps nearly orthogonal), though perhaps there’s redundancies inbuilt into the system (and perhaps the location of the cells might show that)
Backlinks
- [[loftus-and-memory]]
- Reading about the malleability of memory, and relating this to the recent ideas from #neuroscience on how our cells work through linear algebra (see [[rotation-dynamics-in-neurons]] and [[neural-code-for-faces]]), I wonder if there’s a similar way of coding the curious properties of memory as artefacts of linear algebra.
Linguistic Neuroscience
Wild Conjectures
As somewhat of an interdisciplinary nut1 like a gun-nut, except, with interdisciplinary research, instead of guns, duh!, it comes as no surprise that I think the advent of computational linguistics has really helped us better understand language. Something that I try to emphasize in class is the uniqueness of languages and words as a data form. In some (highly reductionist) sense, it’s just categorical data. For one thing, that’s definitely not how we would think about it at the outset, but the moment you start thinking statistically, you realize it’s a very natural formulation. Secondly, there’s all this interesting structure and rules (i.e. grammer), meaning, relationships, logic, intelligence. In fact, as we’ve sort of discovered from [[gpt3]], it is quite the proxy for general intelligence. And in between all this are the distributed semantic representation lessons from #embeddings. But I digress.
A natural question to ask is, are all these things we’ve learned about language and words back-propagatable to the way our brains understand and organize language? It is rather tempting to hope that perhaps the way word embedding representation might be similar to the way our brains encode words. And it turns out that there is empirical evidence to suggest that something interesting is going on, though I need to read the literature more carefully. This piece is an attempt to take a skeptical view of all this.
Firstly, I’m pretty sure that we have no idea how our brains handle words/language. What we can do is the next best thing, which is to see how our brain patterns (i.e. fMRI scans) look like when we hear particular words: that is, we can equate words to “brain activation patterns.”2 I’m being particularly vague here because there are many modalities of such patterns, from using magnets to oxygen levels, the details of which I haven’t been bothered to score into memory.3 This reminds me of conversations from #vbw. Probably many millions of human-brain-hours have been spent tackling this problem, so I don’t think this little brain will make any particularly groundbreaking inroads here.
A few remarks though:
- I think you understand the mechanics of a system best when it’s under stress/strain. In my case, when doing things like word problems/crossword puzzles or just whenever a word is at the tip of your tongue.
- I’m not really sure what space I’m traversing (if any) when I’m reaching for a particular word that’s at the tip of my tongue, but in any case I feel it must be a confluence of sounds/muscle-memory/meaning/memory.
- There must be individually differences in terms of degrees of abstract thought.
- I find that Chinese and English are very different systems in my head (which can be partially explained by my not-so-great Chinese). In particular, I think rather phonetically when it comes to Chinese, which has the funny byproduct that I’m much better at making puns in Chinese than my innate ability would suggest otherwise.
- I just find it hard to believe that the way I reach words in my head is accessing some space: in particular, that would suggest that oftentimes I’ll mistake words that are very close in said space (which rarely happens).
All this is to say: my default position is that the distributed representation of word might be correlated, but that correlation is almost tautological: that is, if you have any good representation of words, then it must necessarily be correlated with the way our brains process words.4 Having written that statement out, it actually feels like quite a strong statement, and I’m not even sure if it’s true. I think what my intuition is getting at is: the act of finding a representation, it’s like collapsing something down to a finite-dimensional vector space. The process of doing so makes any potential equivalence/correlation moot.
The problem is that, what I’ve describe above is almost impossible to falsify!
Another way to frame this is that, the sheer complexity of language means that if you’re squeezing it down5 It’s a little like a compression algorithm. into a small space (\(\mathbb{R}^{300}\))6 Funny how things quickly become small. then there’s no way for any two representations to be uncorrelated?
Literature
(Huth et al. 2016Huth, Alexander G, Wendy A de Heer, Thomas L Griffiths, Frédéric E Theunissen, and Jack L Gallant. 2016. “Natural speech reveals the semantic maps that tile human cerebral cortex.” Nature 532 (7600): 453–58.): looks like there are dedicated regions of the brain that correspond to various semantic types (and it’s pretty consistent across individuals). they do this by forming a generative model. You have local regions (hidden states) that are disjoint and provde full support, which you then learn.
(Fereidooni et al. 2020Fereidooni, Sam, Viola Mocz, Dragomir Radev, and Marvin Chun. 2020. “Understanding and Improving Word Embeddings through a Neuroscientific Lens.” bioRxiv, September, 2020.09.18.304436.): they first show that correlation is significant (but it’s 0.1 (!), which is like…I guess not 0…?). They then find a way to inform word embedding models with data from the features from brain scans (didn’t look at this that carefully, as I don’t really trust some of the authors of this paper).
Relational Learning and Word Embeddings
Literature
Emergence of Analogy
(Lu, Wu, and Holyoak 2019Lu, Hongjing, Ying Nian Wu, and Keith J Holyoak. 2019. “Emergence of analogy from relation learning.” Proceedings of the National Academy of Sciences of the United States of America 116 (10): 4176–81.):
- language learning (relational learning) can be broken down:
- part 1: unsupervised: infant years, when you’re just taking in words. creating building blocks. it’s akin to word embedding models learning from a corpus.
- part 2: supervised: bootstrapping from the above building blocks, can learn higher-order reasoning (relations). akin to small-data, teacher-student model learning.
- to “test” this, we start with word2vec, then do supervised learning on analogy pairs, a crucial point here being that you learn this in a distributed manner (so then analogies have their own space).
- actually, it’s a little more nuanced: you first start with word pairs, then do some kind of preprocessing to make them more useful.
- then they make a fuss about the representation being decomposable by the two words, which has the nice property that if you just swap the positions, you’re basically get the reverse relation.
- this is all aesthetically pleasing, but how to verify?
- not really sure what the results are here…
- they also have problems with antonyms, which was the impetus for my project on [[signed-word-embeddings]].
Predicting Patterns
src: YCC
Psychologists match human performance to differently constructed word relation models (based on Word2Vec). Unsurprisingly they find that the most complicated model (BART) performs the best and best matches human performance, thereby conflating human ability with the raison d’être of BART (learn explicit representations).
Actual Summary:
- word relations (like analogies) are complex (contrast, cause-effect, etc.), ambiguous (friend-enemy could signify contrast or similarity, via the notion of frenemy), graded (warm-cool vs hot-cool)
- similar in spirit to words themselves (i.e. words have similar properties)
- since word embeddings (or the idea of distributed representation) did so much for NLP (and have been shown to be a good approximation for how our brains encode words), perhaps word relations themselves are similarly distributed.
- lets consider Word2Vec in the context of semantic relations
- taking the diff of two vectors does surprisingly well in determining analogies (and was the selling point of (Mikolov et al. 2013Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Distributed representations ofwords and phrases and their compositionality.” In Advances in Neural Information Processing Systems. Google LLC, Mountain View, United States.)), also see [[explaining-word-embeddings]] for a principled reason why taking the difference should work)
- that being said, anyone who’s played around with it will know that it’s not particularly robust
- taking the diff of two vectors does surprisingly well in determining analogies (and was the selling point of (Mikolov et al. 2013Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Distributed representations ofwords and phrases and their compositionality.” In Advances in Neural Information Processing Systems. Google LLC, Mountain View, United States.)), also see [[explaining-word-embeddings]] for a principled reason why taking the difference should work)
- this will be our baseline. we’re going to compare it to BART, which is the weird Bayesian model that they created.
- the nice thing about BART is that it “assumes semantic relations are coded by distributed representations across a pool of learned relations”.
- now, we’re going to use these two models and compare their analogical reasoning against humans.
- lo-and-behold, BART better matches human performance than word2vec-diff.
- I mean, I feel like what I’m saying is just too obvious that there’s no way that they haven’t thought about this.
- they have some robustness claims by referring to the fact that human performance itself was sort of all over the place, in light of the diversity of relations queried (across the two experiments).
- then they have this result: they show that intelligence/cognitive capacity (of the individual) was predictive of clear analogical reasoning (which is generally known) but also of how well BART predicted individual similarity judgement patterns.
- weird result, not really sure what to make of this – feels like it could just be an artefact of the fact that intelligence is correlated with how variable or predictable your answers are, and so affects BART’s ability to predict.
- lo-and-behold, BART better matches human performance than word2vec-diff.