#science
Loftus and Memory
src: New Yorker
Reading about the malleability of memory, and relating this to the recent ideas from #neuroscience on how our cells work through linear algebra (see [[rotation-dynamics-in-neurons]] and [[neural-code-for-faces]]), I wonder if there’s a similar way of coding the curious properties of memory as artefacts of linear algebra.
A few key ideas:
- I assume memory is projected information, and so reconstructing it involves remembering the correct angle
- the malleability, or degradation of memory over time might come from the fact that you’re sharing the same space, and so over time, as you write to the same space (at various angles), you’re inevitably going to get corruption
- a prediction would be that if your ability to form new memories is lost, then you’re going to get much less corruption (though basically that holds for any memory process that involves some sort of overwriting).
- It’s clear that memory and emotions are heavily intertwined, though I don’t see how this model is able to capture that
- It’s also clear that memory and stories are related:
- one way to think about this is that stories are either simple building blocks that help with prediction (i.e. if you have a story framework, then it sort of tells itself).
- so it’s sort of like having lower dimensional representations of our memories, that are able to capture the essense of the memory, without actually having to store all the particulars.
Rotation Dynamics in Neurons
src: (Libby and Buschman 2021Libby, Alexandra, and Timothy J Buschman. 2021. “Rotational dynamics reduce interference between sensory and memory representations.” Nature Neuroscience.)
Cognition, our intelligence, lies, in part, in our ability to synthesize what we see before us (our sensory input) with our store of data (memory, maybe working, maybe long-term). In other words, intelligence is the cumulation of a time-cascade of information. Now, supposedly, due to the “distributed nature of neural coding,” this can lead to interference between the various time-levels.
This part is a little confusing to me, so let’s work through this slowly. Suppose we take a computer as an artificial example: you essentially have different stores of data with different read speeds (which loosely proxy sensory (registers), short-term (RAM) and long-term (disk)).1 In computers, the changing variable is read-speed/distance. Perhaps in the brain, the changing variable is the dimension of the data? Clearly, if you had enough “space,” there wouldn’t be an issue of interference. But of course our brains aren’t constructed to have simple, isolated stores,2 Well, we have neurons, and groups of neurons feel a little like discrete stores. This is where the limits of my knowledge are a crux; I feel like there are things like memory neurons, different templates of (perhaps groups of) neurons. On the other hand, the heavily architected memory components of the latest #deep_learning models cannot possibly be how the brain functions. We’re still missing the #biologically_inspired bit here. so perhaps it’s not even about the space constraint, but just the nature of the form of the “data.”
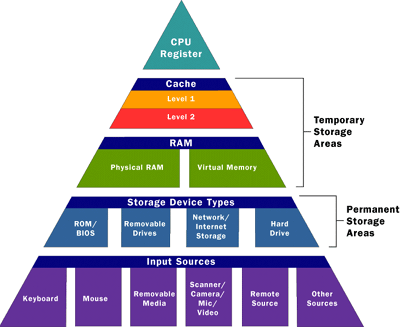 Figure 1: Computer Memory Pyramid
Figure 1: Computer Memory Pyramid
Let’s try and work backwards a little: why would our brains want to orthogonalize things? I think one of the key assumptions is that, for various reasons probably related to the protections afforded by redundancy and distributed representation (or even the noisy, arbitrary nature of life’s input), we represent information as high-dimensional vectors. Under this regime, then it really pays to utilize the whole space. How to do so? The most crude way would be to simply orthogonalize. But, actually, the fact that these vectors become orthogonal might just be a byproduct of some more complex process.
Backlinks
- [[loftus-and-memory]]
- Reading about the malleability of memory, and relating this to the recent ideas from #neuroscience on how our cells work through linear algebra (see [[rotation-dynamics-in-neurons]] and [[neural-code-for-faces]]), I wonder if there’s a similar way of coding the curious properties of memory as artefacts of linear algebra.