#matrix_completion
On Optimization
Statisticians get their first taste of optimization when they learn about penalized linear regression: \[ \begin{align*} \min_{\beta} \norm{Y - X \beta}_2^2 + \lambda\norm{\beta}_p. \end{align*} \] It turns out that there’s an equivalent formulation (as a constrained minimization) that provides a little more intuition: \[ \begin{align*} \min \norm{Y - X \beta}_2^2 \text{ s.t. } \norm{\beta}_p \leq s, \end{align*} \]
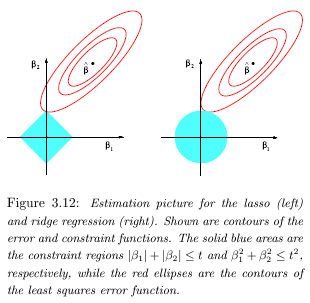 Figure 1: The OG image.
Figure 1: The OG image.
where there is a one-to-one relation between \(\lambda\) and \(s\). This different view provides a geometric interpretation: depending on the geometry induced by the \(l_p\) ball that is the constraint set, you’re going to get different kinds of solutions (see Fig. 1).
Note that the above equivalence is exact only when the loss and the penalty are both convex. In the #matrix_completion setting, with our penalty, this is no longer the case.
The (classical) convex program (Candes and Recht 2009Candes, Emmanuel J, and Benjamin Recht. 2009. “Exact matrix completion via convex optimization.” Foundations of Computational Mathematics 9 (6): 717–72.) is given by: \[ \begin{align*} \min \norm{ W }_\star \text{ s.t. } \norm{ \mathcal{A}(W) - y }_2^2 \leq \epsilon, \end{align*} \] where setting \(\epsilon = 0\) reduces to the noise-less setting. The more recent development using a penalized linear model is given by: \[ \begin{align*} \min_{W} \norm{ \mathcal{A}(W) - y }_2^2 + \lambda \norm{W}_{\star} \end{align*} \] Since they’re both convex, you have equivalence just like for the Lasso.1 I’m pretty sure that people have profitably used this equivalence in this context.
Non-Convex
What happens when we move to non-convex penalties though? Then, I think what you have is a duality gap (I could be wrong). If we use our penalty \(\frac{\norm{W}_{\star}}{\norm{W}_{F}}\), then these two views are no longer equivalent. And here I think actually going back to the penalized loss function gives better results. For one thing, it’s no longer a convex program, amenable to simple solvers.
In our experiments we find that running Adam on this penalized loss function gives great results. My speculation is that this might be the way to solve non-convex programs (I’m sure people have thought about this).