#src:article
Troubles with AI in insurtech
src: CNN
This is the twitter post from Lemonade that caused a raucous:
For example, when a user files a claim, they record a video on their phone and explain what happened.
Our AI carefully analyzes these videos for signs of fraud. It can pick up non-verbal cues[emphasis added] that traditional insurers can’t, since they don’t use a digital claims process. (4/7)
People were concerned by the very likely possibility that Lemonade’s automated claims processing would use such features as a person’s skin-color to gauge the possibility of fraud. From the public’s perspective, this feels like yet another instance of the misapplication of AI, of some computer reading the signals and coming to some conclusion, that might be abhorrent, from a social perspective.
This is going to be common refrain for tech companies that purport to use AI to solve a problem.1 One might want to qualify that by restricting to problems involving people, but that feels like almost redundant. What’s sort of ironic is that Lemonade has really oversold their AI capabilities, and what they claim to be AI is probably some straightforward model. This comes from having read their S1 document fairly closely, and realizing stuff like their AI chat bots is nothing more than a prettified question flowchart.
With the advent of AI-based solutions to everything under the sun, most of which are black-boxes, I feel like there’s going to be a need for some sort of auditing body. I mean, you’re not going to be able to stop the flow of investor money during what I guess one can be called the “AI Spring” to these companies. The solution then is to be able to say that you’ve been audited, certified.2 In the short term, I think what we’ll probably see is that companies are going to learn to keep quiet on social media (mob mentality more likely to converge to disgust). It’s tricky, because for a product like what Lemonade is offering, their target audience is exactly those on social media.
Of course, what remains is the most difficult question: determining whether a model is unfit to be used publicly, perhaps because it’s unfair. And so we’re back to the [[project-fairness]].
Let’s linger on this particular problem for a little bit:
- I definitely think facial recognition is a much more visceral example than finding patterns in tabular data. Thus, the first rule should be to never use facial data as part of your AI engine (or, downplay it, obfuscate).
Backlinks
- [[202106011119]]
- Problems with Lemonade: [[troubles-with-ai-in-insurtech]]
Loftus and Memory
src: New Yorker
Reading about the malleability of memory, and relating this to the recent ideas from #neuroscience on how our cells work through linear algebra (see [[rotation-dynamics-in-neurons]] and [[neural-code-for-faces]]), I wonder if there’s a similar way of coding the curious properties of memory as artefacts of linear algebra.
A few key ideas:
- I assume memory is projected information, and so reconstructing it involves remembering the correct angle
- the malleability, or degradation of memory over time might come from the fact that you’re sharing the same space, and so over time, as you write to the same space (at various angles), you’re inevitably going to get corruption
- a prediction would be that if your ability to form new memories is lost, then you’re going to get much less corruption (though basically that holds for any memory process that involves some sort of overwriting).
- It’s clear that memory and emotions are heavily intertwined, though I don’t see how this model is able to capture that
- It’s also clear that memory and stories are related:
- one way to think about this is that stories are either simple building blocks that help with prediction (i.e. if you have a story framework, then it sort of tells itself).
- so it’s sort of like having lower dimensional representations of our memories, that are able to capture the essense of the memory, without actually having to store all the particulars.
Reflexivity
Core Idea:
- fallibility: “in situations that have thinking participants, the participants’ view of the world is always partial and distorted”
- reflexivity: “these distorted views can influence the situation to which they relate because false views lead to inappropriate actions”
Reflexivity:
- thinking participants:
- cognitive function: understanding the world (world -> mind)
- manipulative function: affecting the world (mind -> world)
- knowledge = true statements
- “if there is interference from the manipulative function, the facts no longer serve as an independent criterion by which the truth of a statement can be judged”
- e.g. “This is a revolutionary moment.” That statement is reflexive, and its truth value depends on the impact it makes.1 I mean, I get what he’s trying to do, but I think he’s delving too deeply into epistemology for no good reason. It’s not about the veracity of a statement, but about the power of words to be self-fulfilling (i.e. have consequences down the road)
In the real world, the participants’ thinking finds expression not only in statements but also, of course, in various forms of action and behavior. That makes reflexivity a very broad phenomenon that typically takes the form of feedback loops. The participants’ views influence the course of events, and the course of events influences the participants’ views. The influence is continuous and circular; that is what turns it into a feedback loop.
Feedback loops:
- can be either positive or negative
- negative: brings view and situation closer together, positive: further apart2 is this right? at the very least that’s not how I thought about it.
- negative = self-correcting (and leads to equilibrium)
- positive = self-reinforcing
- cannot go on forever, because the view would be too far from reality
We
src: New Yorker
For decades, venture capitalists have succeeded in defining themselves as judicious meritocrats who direct money to those who will use it best. But examples like WeWork make it harder to believe that V.C.s help balance greedy impulses with enlightened innovation. Rather, V.C.s seem to embody the cynical shape of modern capitalism, which too often rewards crafty middlemen and bombastic charlatans rather than hardworking employees and creative businesspeople. Jeremy Neuner, the NextSpace co-founder, said, “You can’t blame Adam Neumann for being Adam Neumann. It was clear to everyone he was selling something too good to be true. He never pretended to be sensible, or down to earth, or anything besides a crazy optimist. But you can blame the venture capitalists.” Neuner went on, “When you get involved in the startup world, you meet all these amazing entrepreneurs with fantastic ideas, and, over time, you watch them get pushed by V.C.s to take too much money, and make bad choices, and grow as fast as possible. And then they blow up. And, eventually, you start to realize: no matter what happens, the V.C.s still end up rich.” ♦
I know there have been #money_stuff posts that talk about the reality-distorting effect of VC money, even while you can probably make a case for it,1 The typical argument is that you need to get to a certain scale/market penetration to reach profitability (due to things like network effect and whatnot), which almost feels like you’re saying you need to be a monopoly to win. but they clearly create perverse incentives and completely break down the free function of capitalism to weed out the cruft.
However, this second part is probably worth pondering over, that the V.C.s, even while making such terrible bets (like WeWork) are still able to come out on the other side making a substantial profit. The gist of the article is that, given the potentially incredible pay-out if WeWork were to IPO, there was very little incentive for the Board of Directors to question or intervene, which is counter to their fiduciary duty to all shareholders, and so the Board essentially gave Neumann free reign, up until the point where it was clear that an IPO wouldn’t proceed (after the revelations from the S1 and journalists, which shows the purpose and power of public markets and the press). The losers in this were the employees (whose stock options became worthless), and the various investors that bought at the peak (including some mutual funds?). I mean, in some sense (and probably this is just stolen from #money_stuff again), this is just what happens in the wild-wild-west of private markets, where there is little oversight; it’s not like the V.C.s actively defrauded people (?), they just propped up and propelled a dream that was too good to be true.
All that being said, it does seem like this environment does create perverse incentives for the V.C.s, since it is no longer necessary to pick the best horse; if you’ve picked the wrong horse (or the horse falters before the finish line), as long as you shower it and dazzle the crowd, you can eventually pawn it off. Not really sure how to correct the market here (though the spectacular failure of We has done much to offset the irrational exuberance, though not sure if it has changed the calculus).
The Search for Meaning
src: New Republic
As I wrote earlier this year, I long viewed the Japanese fondness for sanitary masks as evidence of some deep-seated cultural defect. Now that I wear a mask myself every day, it’s amazing to me that I could not see the obvious, banal reason people use masks: to protect their health.
Following on from yesterday’s piece about [[new-medium]], here we have another example of revelations on the veracity of a (this time New Yorker) story, about the phenomenon of rental families in Japan. At the onset, this piece is about the West’s fetishization of Japan, that depicts it as “a menagerie of the weird, the alien, the freakish”. But then it shifts gears, and calls into the question of the idea of stories, and the need for some kind of narrative or explanation.
Clearly, that’s how we function as humans (and in particular as academics). That’s also how I operate: finding patterns and grand theories in the vagaries of the real world. And perhaps that’s actually a strong bias, and in much the same way that journalists have some kind of narrative that they’re trying to push, however innocuous it may be, it might help contextualize the problems similarly faced in academia. The problem is that, if we don’t have the stories, the ability to generalize, then we really have nothing as academics. The stakes seem even higher for us.
Death of Value Investing
src: Economist
- value investing: using price-to-book ratio (or price-earnings ratio) as a measure of value to determine under-valued stocks
- easy in the old days of the industrial era, where assets were tangible.
- good track record of passing over bubbles (i.e. dot-com boom), since those stocks had bad ratios. but then missed the boat on the recent tech boom.
- the idea being that if you stick to fundamentals, these stocks will ride out any irrational exuberance.
- now, developed economies are dominated by the service sector, tech companies dominate the market. their assets are intangible, so the metric of price-to-book means you miss out on tech stocks (à la Buffet).
- software
- patents
- ideas
- supply chains (somewhat in between the two)
- skills/knowledge/know-how
- culture (Bridgewater Associates?)
- recently, value stocks have underperformed the market, lending empirical credence to the above
- new value (via the book “Capitalism without Capital”):
- digital goods, intangible, have infinite scalability, since not limited to physical space
- network effects
- higher sunk costs: intangibles are harder to both measure and transfer around, given their ethereal nature
- ideas have spillover, since they’re easy to replicate.
- synergies abound in the realm of ideas, as it’s easier to experiment, very little start-up cost
- digital goods, intangible, have infinite scalability, since not limited to physical space
- all of this is difficult to measure/extrapolate from a company’s books (again with the measurement problem)
- more at stake, since network effects give rise to winner-takes-all

In an economy mostly made up of tangible assets you could perhaps rely on a growth stock that had got ahead of itself to be pulled back to earth, and a value stock that got left behind to eventually catch up. Reversion to the mean was the order of the day. But in a world of increasing returns to scale, a firm that rises quickly will often keep on rising.
- how does one determine some intrinsic value in today’s market?
- differentiating between bubbles and true value is much harder now.
Openendedness
src: article
Comes from the same people as [[why-greatness-cannot-be-planned]].
Next Steps for Deep Learning
src: Quora
Deep Learning 1.0
Limitations:
- training time/labeled data: this is a common refrain about DL/RL, in that it takes an insurmountable amount of data. Contrast this with the [[bitter-lesson]], which claims that we should be utilizing computational power.
- adversarial attacks/fragility/robustness: due to the nature of DL (functional estimation), there’s always going to be fault-lines.
- selection bias in training data
- rare events/models are not able to generalize, out of distribution
- i.i.d assumption on DGP
- temporal changes/feedback mechanisms/causal structure?
Deep Learning 2.0
Self-supervised learning—learning by predicting input
- Supervised learning : this is like when a kid points to a tree and says “dog!”, and you’re like, “no”.
- Unsupervised learning : when there isn’t an answer, and you’re just trying to understand the data better.
- classically: clustering/pattern recognition.
- auto-encoders: pass through a bottleneck to reconstruct the input (the main question is how to develop the architecture)
- i.e. learning efficient representations
- Semi-supervised learning : no longer just about reconstructing the input, but self-learning
- e.g. shuffle-and-learn: shuffle video frames to figure out if it’s in the correct temporal order
- more about choosing clever opjectives to optimize (to learn something intrinsic about the data)
The brain has about 10^4 synapses and we only live for about 10^9 seconds. So we have a lot more parameters than data. This motivates the idea that we must do a lot of unsupervised learning since the perceptual input (including proprioception) is the only place we can get 10^5 dimensions of constraint per second.
Hinton via /r/MachineLearning.1 I’m not sure I follow the logic here. My guess is that you have a dichotomy between straight up perceptual input and actually learning by interacting with the world. But that latter feedback mechanism also contains the perceptual input, so it should be at the right scale.
- much more data than supervised or #reinforcement_learning
- if coded properly (like the shuffle-and-learn paradigm), then it can learn temporal/causal notions
- utilization of the agent/learner to direct things, via #attention, for instance.
Figure 1: Newborns learn about gravity at 9m. Pre: experiment push car off and keep it suspended in air (with string) won’t surprise. Post: surprise.
- case study: BERT. self-supervised learning, predicting the next word, or missing word in sentence (reconstruction).
- not multi-sensory/no explicit agents. this prevents it from picking up physical notions.
- sure, we need multi-sensory for general-purpose intelligence, but it’s still surprising how far you can go with just statistics
- not multi-sensory/no explicit agents. this prevents it from picking up physical notions.
- less successful in image/video (i.e. something special about words/language).2 Could it be the fact that we deal with already highly representative objects that are already classifications of a sort, whereas everything else is at the bit/data level, and we know that’s not really how we process such things. This suggests that we should find an equivalent type of language/vocabulary for images.
- we operate at the pixel-level, which is suboptimal
- prediction/learning in (raw) input space vs representation space
- high-level learning should beat out raw-inputs3 My feeling though is that you eventually have to go down to the raw-input space, because that is where the comparisons are made/the training is done. In other words, you can transform/encode everything into some better representation, but you’ll need to decode it at some point.
Leverage power of compositionality in distributed representations
- combinatorial explosion should be exploited
- composition: basis for the intuition as to why depth in neural networks is better than width
Moving away from stationarity
- stationarity: train/test distribution is the same distribution
- they talk about IID, which is not quite the same thing (IID is on the individual sample level—the moment you have correlations then you lose IID)
- not just following #econometrics, in that the underlying distributions are time-varying though
- feedback mechanisms (via agents/society) require dropping IID (and relate to [[project-fairness]])
- example: classifying cows vs camels reduces to classifying desert vs grass (yellow vs green)
- not sure how this example relates, probably need to read [[invariant-risk-minimization]]
Causality
- causal distributed representations (causal graphs)
- allows for causal reasoning
- it’s a little like reasoning in the representation space?
Lifelong Learning
- learning-to-learn
- cumulative learning
Bitter Lesson
src: blog
Summary
In AI research, leveraging computation > incorporating domain knowledge. Given finite resources, it always pays to improve computation than to incorporate domain knowledge.
the only thing that matters in the long run is the leveraging of computation
This bitter lesson arises in part because of our anthropocentric view (that’s not how we as humans solve insert_difficult_task!), biasing us towards more elaborate systems.
And the human-knowledge approach tends to complicate methods in ways that make them less suited to taking advantage of general methods leveraging computation.
Also, there’s a trade-off, especially as the injection of human knowledge gets more elaborate, then there’s usually a computation cost.
History
- Chess: search-based approaches beat out leveraging human understanding of structure of chess
- Go: key insight was learning by self-play, which enabled massive computation to be brought to bear
- Speech Recognition: linguistics, we have the Unreasonable Effectiveness paper of Norvig
- More recently, the massive scale language models (like GPT-3) show that larger models/datasets outperform fancier architectures (and history repeats itself)
We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovering process can be done.
Even though a lot of our knowledge is guided, for most of our general-purpose intelligence, it just happens naturally, so it should be similarly for building AI.
Remarks
I’m not as familiar with the AI game literature, but at least in the context of NLP/image classification and DL, there seems to be an ideal sweet-spot in terms of finding the right kind of architecture that’s powerful enough to learn, but is simple enough that you can run it on an extreme scale. I think that’s partly why we still continue to innovate on the model side. If we hadn’t done so, then we wouldn’t have gotten [[transfer-learning]], which has been a boon for NLP.
What is pretty clear is that domain-knowledge injection is not scalable (think expert systems back in the day). What’s better are general-purpose methodologies, and the more general-purpose, the better. However, this would suggest that something like CNNs are actually suboptimal, since convolutions are definitely highly specific to image classification. But I think that’s part of the allure of [[graph-neural-networks]].
Given the successes of CNN in image recognition, I suspect that for specific domain tasks, a little bit of domain knowledge can go a very long way (it’s not like it’s hard-coding edge detection, so it’s still pretty general purpose).
Finally, it feels like we just need to be better at learning-to-learn. I don’t think it’s necessarily a bad thing to take inspiration from human intelligence (since we’re the only successful example). So, ultimately, I think the bitter lesson is really just a stop-gap until we can sufficiently narrow the emulation gap.
Backlinks
- [[next-steps-for-deep-learning]]
- training time/labeled data: this is a common refrain about DL/RL, in that it takes an insurmountable amount of data. Contrast this with the [[bitter-lesson]], which claims that we should be utilizing computational power.
Exponential Learning Rates
via blog and (Li and Arora 2019Li, Zhiyuan, and Sanjeev Arora. 2019. “An Exponential Learning Rate Schedule for Deep Learning.” arXiv.org, October. http://arxiv.org/abs/1910.07454v3.)
Two key properties of SOTA nets: normalization of parameters within layers (Batch Norm); and weight decay (i.e \(l_2\) regularizer). For some reason I never thought of BN as falling in the category of normalizations, ala [[effectiveness-of-normalized-quantities]].
It has been noted that BN + WD can be viewed as increasing the learning rate (LR). What they show is the following:
The proof holds for any loss function satisfying scale invariance: \[ \begin{align*} L(c \cdot \theta) = L(\theta) \end{align*} \] Here’s an important Lemma:
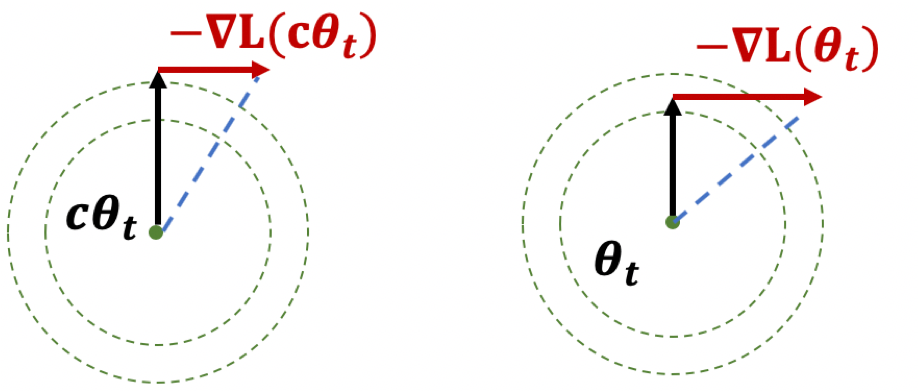 Figure 1: Illustration of Lemma
Figure 1: Illustration of Lemma
The first result, if you think of it geometrically (Fig. 1), ensures that \(|\theta|\) is increasing. The second result shows that while the loss is scale-invariant, the gradients have a sort of corrective factor such that larger parameters have smaller gradients.
Thoughts
The paper itself is more interested in learning rates. What I think is interesting here is the preoccupation with scale-invariance. There seems to be something self-correcting about it that makes it ideal for neural network training. Also, I wonder if there is any way to use the above scale-invariance facts in our proofs.
They also deal with learning rates, except that the rates themselves are uniform across all parameters, make it much easier to analyze—unlike Adam where you have adaptivity.
Explaining Word Embeddings
- blog:
- gives an “intuitive” explanation for why Word Embeddings should satisfy analogies
- which is pretty straightforward
- Words close in this space are often synonyms (e.g. happy and delighted), antonyms (e.g. good and evil) or other easily interchangeable words (e.g. yellow and blue).
- this relates to a project that has been at the back of my mind, [[signed-word-embeddings]]
- this is an important concept: that you should be getting “interchangeability” not closeness in meaning, though they are proxies
- this feels like an open question, right?
- a is to b is as A is to B gives \(\frac{P(w|a)}{P(w|b)} = \frac{P(w|A)}{P(w|B)}\)
- dog is to puppy as cat is to kitten
- \(\frac{P(w|dog)}{P(w|puppy)} = \frac{f(w\vert age=adult)}{f(w\vert age=cub)} = \frac{P(w|cat)}{P(w|kitten)}\)
- you’re sort of decomposing as follows:
- \[\displaylines{P(w\vert dog) = f(w\vert species=dog) \times f(w\vert age=adult) \times P(w\vert is\_a\_pet) \\ P(w\vert puppy) = f(w\vert species=dog) \times f(w\vert age=cub) \times P(w\vert is\_a\_pet) \\ P(w\vert cat) = f(w\vert species=cat) \times f(w\vert age=adult) \times P(w\vert is\_a\_pet) \\ P(w\vert kitten) = f(w\vert species=cat) \times f(w\vert age=cub) \times P(w\vert is\_a\_pet)}\]
- that’s how the ratios end up being the same, because you’re basically cancelling the shared “hidden variables”
- this makes it feel like a hidden variable type thing?
- you’re sort of decomposing as follows:
- \(\frac{P(w|dog)}{P(w|puppy)} = \frac{f(w\vert age=adult)}{f(w\vert age=cub)} = \frac{P(w|cat)}{P(w|kitten)}\)
- gives an “intuitive” explanation for why Word Embeddings should satisfy analogies
Todo
- recent paper exploring this further: blog
Backlinks
- [[relational-learning]]
- taking the diff of two vectors does surprisingly well in determining analogies (and was the selling point of (Mikolov et al. 2013Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Distributed representations ofwords and phrases and their compositionality.” In Advances in Neural Information Processing Systems. Google LLC, Mountain View, United States.)), also see [[explaining-word-embeddings]] for a principled reason why taking the difference should work)
Problems with Machine Learning Scholarship
via Science.
- Pruning: [[network-pruning]]
- Recommendation Systems: seems like it’s not all good news on this front either: (Dacrema, Cremonesi, and Jannach 2019Dacrema, Maurizio Ferrari, Paolo Cremonesi, and Dietmar Jannach. 2019. “Are we really making much progress? A worrying analysis of recent neural recommendation approaches.” In RecSys 2019 - 13th Acm Conference on Recommender Systems, 101–9. New York, NY, USA: Politecnico di Milano, Milan, Italy; ACM.)
- Metric Learning (arXiv): looking at different loss functions doesn’t really help that much.
- Adversarial Training: (Rice, Wong, and Kolter 2020Rice, Leslie, Eric Wong, and J Zico Kolter. 2020. “Overfitting in adversarially robust deep learning.” arXiv.org, February. http://arxiv.org/abs/2002.11569v2.)
Graph Network as Arbitrary Inductive Bias
src.
The architecture of a neural network imposes some kind of structure that lends itself to particular types of problem (CNN, RNN). Thus, you can think of this as some form of inductive bias. An interesting view of [[graph-neural-networks]] is that essentially these provide arbitrary inductive bias, since the goal is to learn the architecture?
| Component | Entities | Relations | Inductive Bias | Invariance |
|---|---|---|---|---|
| FC | Units | All-to-all | Weak | - |
| Conv. | Grid elements | Local | Locality | Spatial transl. |
| Recurrent | Time | Sequential | Sequentially | Time transl. |
| Graph | Nodes | Edges | Arbitrary | V,E permute |
From (Battaglia et al. 2018Battaglia, Peter W, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, et al. 2018. “Relational inductive biases, deep learning, and graph networks.” arXiv.org, June. http://arxiv.org/abs/1806.01261v3.)
(Though, is that really what GNNs really do?)
Market for Lemons
via FT’s Free Lunch.
Nobel Laureate George Arkerlof’s paper on “The Market for Lemons”
It was a pioneering analysis of how markets fail to achieve efficient transactions when consumers have worse information about the product than the sellers. In the used-car example, because some unscrupulous used-car traders try to pass off “lemons” as “peaches”, consumers are aware that not all cars are what they seem to be, and discount the value they are willing to put even on the cars of perfectly respectable sellers. Because it is hard to distinguish lemons and peaches in the dealership yard, all used cars are tarnished by this risk.
I talked about this in my Introduction to Economics class, on a simple example of inefficient markets. Interestingly, you can think of #misinformation along the same lines, as a marketplace of ideas, as well as recent riots:
These provocations are, therefore, of a piece with social media propaganda campaigns that spread misinformation. Again, trust is the casualty: the effect of misinformation is not so much to spread false beliefs as to eliminate confidence in truthful ones. As the title of a book by Peter Pomerantsev captures so well, the outcome is that “nothing is true and everything is possible”.
We should understand the effect of agents provocateurs in America’s equal justice protests in the same way. The effect of seeding vandalism and rioting amid the protests is to make it hard to distinguish legitimately angry but peaceful protesters from violent mobs. As a result all are tarred with the same brush.
AB Testing in Networks
source: h.
Summary
- Typical A/B testing (RCT) is done uniformly across the whole population.
- the resolution of the \(t\)-statistic across treatment and control assumes that the TE is independent of treatment
- this assumption is usually treated as given, but difficulties when subjects can interact
- example: group effect, if enough of your friends have the treatment, then you’ll respond positively
- when you have (social) networks, or just people interacting on the same system, what to do?
- expand your unit of experiment: instead of subject, just find components in your graph. to be explicit, this simply means assigning the same treatment to all those in that component.
- however, in most social network settings, we have a very large component (and you get small diameter for free)
- then you’re basically stuck. you could partition into subgroups, but there will always be edges between groups
- could turn into a graph cut problem, aka community detection problem, where you’re finding a partition that minimizes connecting edges.
- in certain settings, the networks are collections of small components. then you’re good to go.
- however, in most social network settings, we have a very large component (and you get small diameter for free)
- my feeling/intuition is that academics will try to measure this network effect. getting into #causal_inference territory.
- oftentimes, this is done post-hoc, so rerunning the experiment is not possible.
- expand your unit of experiment: instead of subject, just find components in your graph. to be explicit, this simply means assigning the same treatment to all those in that component.
- so, if you widen your unit, you’re going to lose power
- fewer experimental units
- differences in units (large vs small, different behaviours)
- it’s like the propensity matching problem, you want similar units, so it’s easier to extract the treatment effect
- solution, part (a): do matching, but in a stratified way
- solution, part (b): expand your model
- the usual model is \(y_i \sim \mu + \tau t_i\), where \(t_i\) is indicator function of treatment, and \(\tau\) is our (average) treatment effect.
- because we have these mini-units, we can do some further modelling here, so that our response is not just a function of the treatment \(t_i\), but also a function of the groups within this unit.
- spill-over effects:
- \(y_i \sim \mu + \tau t_i + \gamma a_i \cdot T\), where \(a_i\) is the column of the adjacency matrix, and \(T\) is the vector of treatments, so \(a_i \cdot T\) is just a cute way to count the number of neighbors
- since by definition, a neighbour must be in the same treatment, you can just replace \(T\) with the ones vector.
- this is a first-order spill-over effect, and it seems like it is simply additive.
Highlights
One particular area involves experiments in marketplaces or social networks where users (or randomized samples) are connected and treatment assignment of one user may influence another user’s behavior.
Typical A/B experiments assume that the response or behavior of an individual sample depends only on its own assignment to a treatment group. This is known as the Stable Unit Treatment Value Assumption (SUTVA). However, this assumption no longer holds when samples interact with each other, such as in a network. An example of this is when the effects of exposed users can spill over to their peers.
Experiments in social networks must care about “spillover” or influence effects from peers.
we lose experimental power. This comes from two factors: fewer experimental units, and greater inherent difference across experimental units.
cluster samples into more homogeneous strata and sample proportionately from each stratum.
Another aspect of concern is that treatment can in theory affect not just experiment metrics but also the graph topology itself. Thus graph evolution events also need to be tracked over the course of the experiment.