#src:podcast
On Single Point Forecasts for Fat Tailed Variables
Using tools from extreme value theory (EVT), Cirillo and Taleb [1] determined that pandemics are patently fat tailed (with a tail exponent patently in the heaviest class: \(α < 1\)) — a fact that was well known (and communicated by Benoit Mandelbrot) but not formally investigated.
Pandemics are fat-tailed.
Random variables with unstable (and uninformative) sample moments may still have stable tail properties centrally useful for inference and risk taking.
RVs with undefined first (and second) moments are still parameterizable (e.g. Cauchy, and stable distributions).
From Wiki:
Many—notably Benoît Mandelbrot as well as Nassim Taleb—have noted this shortcoming of the normal distribution model and have proposed that fat-tailed distributions such as the stable distributions govern asset returns frequently found in finance.
For matters of survival, particularly when systemic, under such classes as multiplicative pandemics, we require “evidence of no harm” rather than “evidence of harm”.
Basically, if you have a fat-tailed distribution, and don’t have enough data to determine the properties of this particular sample, then expect the worst (since your sample moments are uninformative).
He then goes on to explain how, with fat-tailed distributions, confidence levels of the moments are too large to be practically useful (since second moments are so large).
Reference
- CV: difference between finite and infinite moments, goes through an example with the Pareto distribution
Meta Analysis vs Preregistration
src: Expertise of Death, Black Goat Podcast
How important is expertise in conducting replications? Many Labs 4 was a large, multi-lab effort that brought together 21 labs, running 2,220 subjects, to study that question. The goal was to compare replications with and without the involvement of the original authors to see if that made a difference. But things got complicated when the effect they chose to study – the mortality salience effect that is a cornerstone of terror management theory – could not be replicated by anyone.
The somewhat crazy thing is that a comprehensive meta-analysis was conducted for terror management theory, via (Burke, Martens, and Faucher 2010Burke, Brian L, Andy Martens, and Erik H Faucher. 2010. “Two decades of terror management theory: a meta-analysis of mortality salience research.” Personality and Social Psychology Review : An Official Journal of the Society for Personality and Social Psychology, Inc 14 (2): 155–95.). In particular, it was “164 articles with 277 experiments”. That’s a lot of experiments. Things like funnel plots don’t help either (Figure 1).
Figure 1: Funnel Plot in the paper.
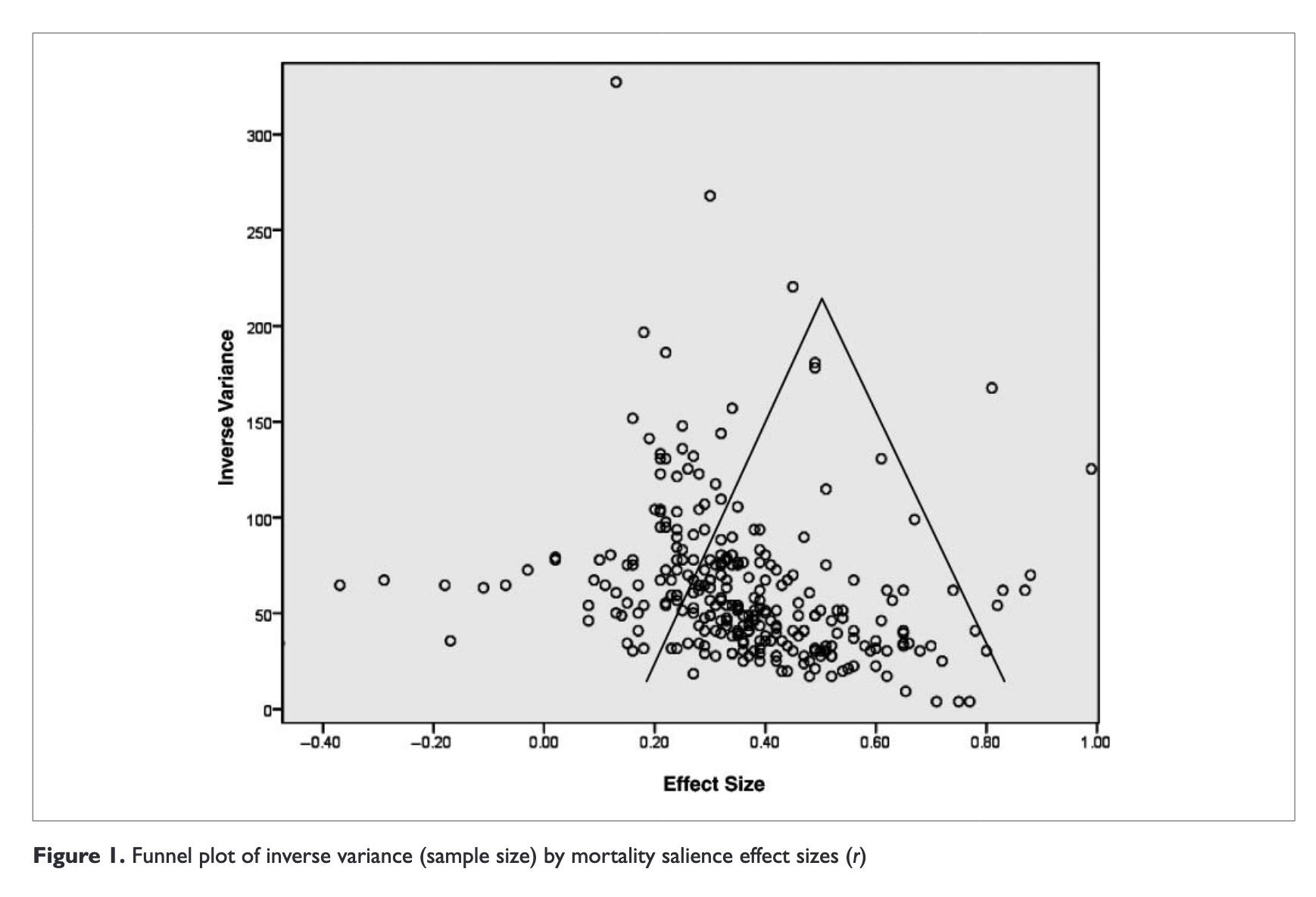
The important question is: are there any meta-analysis techniques that would be able to flag somthing wrong with these experiments? I’m pretty sure the answer here is no. Though, I would loved to be proved wrong. As one of the podcasters remarked, doing a meta-analysis cannot beat doing a large preregistered study.
The problem with meta-analyses is that they assume that the \(p\)-values are drawn from the true distribution, without any bias or problems with the experimental design. But that’s an unreasonable assumption. What is the point of a meta-analysis if not to help combat this replication crisis? I thought the point was that you’re able to detect cases of \(p\)-hacking.
Episode with Ilya
source: AI Podcast
- the recent breakthrough for NLP has been #transformers. it turns out that the key contribution is not just the notion of #attention, but that it’s removed the sequential aspect of
RNN, which allows for much faster training (and for some reason this allows for more efficient GPU training).- which, at a higher level, simply means that if you can train larger versions of these deep learning models, they will oftentimes just do better
- he makes a claim about how, when training a #language_model with an LSTM, if you increase the size of the hidden layer, then eventually you might get a hidden node that is a sentiment node. in other words, in the beginning, the model is capturing more lower-level features of the data. but as you increase the capacity of the model, it’s able to capture more high level concepts, and it does so naturally, just given the model capacity.
- which essentially argues for just having larger and larger models, as you’ll just get more emergent behaviour