Experimental Logs for Matrix Completion
tags: [ proj:penalty , experiments , matrix_completion ]
Logs
Here we focus on the linear model (depth-1) version.
- Obs: if you look at the pattern of convergence, you find that generally speaking the first thing that happens is that the training error gets to zero (interpolation regime).
- this led us to try to initialize at the partially observed data, which works!
- Obs: Adam works very well, but GD works pretty well too. By work well, I am talking about getting decently close to the true singular vectors.1 This is achieved by tracking the inner product of the singular vectors of the estimated matrix and the true singular vectors.
- Obs: actually, even if you use the nuclear norm, you’re going to get “pretty good” results, in that the inner products are getting close to 1.
- my intuition was that the difficulty with this problem was getting anywhere close to the right directions for the singular vectors. In my mind, that seemed to be the difficult thing, so the fact that PGD was pushing it pretty uniformly towards the truth, I thought was a sign that something important was going on.2 This is not a reason, but also, many proofs (in the matrix factorization case) are of the form whereby you have to be clever with your initialization so that you can get into the basin, at which point the problem becomes strongly convex.
- But as it turns out, the difficulty at this level is at the last mile, so to speak. For instance, we already know that the nuclear norm minimizer is no longer the optimal solution. But it’s not like this solution is completely off.
- Obs: the nuclear norm minimum solution in the data-poor regime has decently high inner product with the ground truth singular vectors (\(\approx 0.9\)).
- thus, we have to focus on being able to essentially recover it exactly. Originally I thought some kind of SVD would do the trick, but I don’t think that’s the case.
- Obs: the ratio minimum should coincide with that of the rank. The nuclear norm minimum has higher ratio than the truth, and the sub-optimal solution that the PGD will converge to is also larger than the truth.
- Obs: if you compare the distribution of the singular values, we see that the top ones are smaller, while the bottom are larger (nuclear vs ratio, and ratio vs truth). Essentially, it’s able to find something that is able to match the observations but have smaller nuclear norm.
- this suggests that there are suboptimal optima (that somehow Adam is able to side-step). It feels that this ratio is better able to handle the data-sparse regime. Fig. 1 shows the trade-off that the nuclear norm creates, whereas the ratio penalty doesn’t make the same mistake.
- keep in mind though that the singular vectors are not exactly exactly the same either. so both are perturbed.
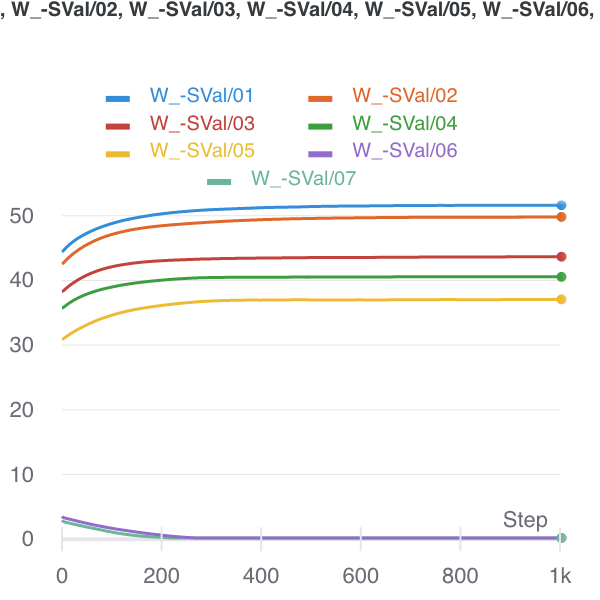 Figure 1: Nuclear Norm minimizer (initialized there) to Ratio Local minimizer.
Figure 1: Nuclear Norm minimizer (initialized there) to Ratio Local minimizer.
- Obs: even moving to rank-1, what we can see that the top singular value is dampened, and a collection of small singular vectors/values are able to recreate that loss in the magnitude.
- basically, the problem is, for a given set of entries (I think they can be arbitrary, even though they’re proportional to the true matrix), with a fixed cost for the total norm, but complete freedom with respect to everything else, can you recreate those entries?
- It would be interesting to investigate why our ratio fails: is it a similar kind of failure, where you’re moving some of the mass from the top to the bottom; or, as I expect, it’s going to be a more catastrophic failure, whereby all structure is destroyed, and so it’s basically hopeless to find the truth?
- From Fig. 2, it looks like what happens when the ratio fails, is that you basically start to separate out the singular values. The singular vectors are still roughly right. This suggests something even more elaborate that takes into account variability. Perhaps the spectral norm (max singular value) might do the trick (though this does not admit a computationally-efficient form/gradient).
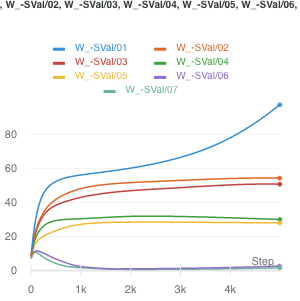 Figure 2: How the ratio penalty fails, with sample size of 1200.
Figure 2: How the ratio penalty fails, with sample size of 1200.
- Obs: trying the noisy version of PGD doesn’t actually do anything.
- feels like it’s not saddle points, so there are actually local minima in the landscape induced by this ratio penalty.
Conclusion
Define \(S^m = \left\{ M : P_{\Omega}(M - M^\star) = 0; \abs{\Omega} = m \right\}\). Then, as you decrease the sample size, \(\abs{\Omega}\), this set grows. For the most part, the nuclear norm min in \(S\) is the truth. But, at some point, this is no longer the case. Let’s actually define an increasing sequences of sets \(\Omega^m\). Then, \(S^m \supset S^{m+1}\). At that point, there is a matrix in \(S^m \setminus S^{m+1}\) with smaller nuclear norm.
From the experiments, it appears that at this boundary condition, this matrix with smaller nuclear norm is very similar to the true matrix. Qualitatively, it seems as if it’s been perturbed, and the singular values dampened, and then noisy singular vectors are introduced to reconstruct the observed entries. Unfortunately, I can’t really think of a principled manner in which to demonstrate this. Perhaps the most fruitful thing here would be to argue in terms of the two norms.
Suppose we’re at the truth (\(M^\star\)). Then perhaps one way to think about what happens is the following: we can always take a step in the direction of the gradient of the nuclear norm from the truth. It just so happens that once your \(S^m\) is sufficiently small, that projection step no longer counteracts the change in norm.
Backlinks
- [[matrix-factorization-to-linear-model]]
- Update: following on from [[experimental-logs-for-matrix-completion]], we have looked at how the nuclear norm fails in the depth-1 case, which is that you dampen the top singular values and reconstruct the residuals from small singular vectors (feels ever so slightly like [[benign-overfitting-in-linear-regression]]).