Exponential Learning Rates
tags: [ src:paper , src:article , lit_review , gradient_descent , optimization ]
via blog and (Li and Arora 2019Li, Zhiyuan, and Sanjeev Arora. 2019. “An Exponential Learning Rate Schedule for Deep Learning.” arXiv.org, October. http://arxiv.org/abs/1910.07454v3.)
Two key properties of SOTA nets: normalization of parameters within layers (Batch Norm); and weight decay (i.e \(l_2\) regularizer). For some reason I never thought of BN as falling in the category of normalizations, ala [[effectiveness-of-normalized-quantities]].
It has been noted that BN + WD can be viewed as increasing the learning rate (LR). What they show is the following:
The proof holds for any loss function satisfying scale invariance: \[ \begin{align*} L(c \cdot \theta) = L(\theta) \end{align*} \] Here’s an important Lemma:
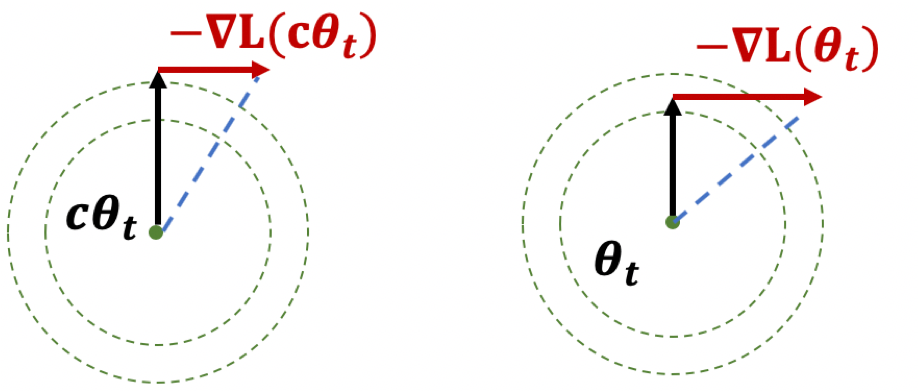 Figure 1: Illustration of Lemma
Figure 1: Illustration of Lemma
The first result, if you think of it geometrically (Fig. 1), ensures that \(|\theta|\) is increasing. The second result shows that while the loss is scale-invariant, the gradients have a sort of corrective factor such that larger parameters have smaller gradients.
Thoughts
The paper itself is more interested in learning rates. What I think is interesting here is the preoccupation with scale-invariance. There seems to be something self-correcting about it that makes it ideal for neural network training. Also, I wonder if there is any way to use the above scale-invariance facts in our proofs.
They also deal with learning rates, except that the rates themselves are uniform across all parameters, make it much easier to analyze—unlike Adam where you have adaptivity.